Key Takeaways
- Keyword research stalls at the writer handoff because volume-sorted exports hide concept structure; treat research as the first stage of brief assembly, not a separate deliverable 2.
- Structure every brief around four expansion layers — concepts, synonyms, variants, and intent tags — and a six-field schema covering primary term, intent, cluster, synonyms, SERP type, and satisfaction criteria.
- Automation belongs in research, expansion, and SERP classification; the strategist approval gate before drafting is what keeps the pipeline on the supported side of Google's helpful content guidance 1.
- Focus next on the four-question approval check — SERP fit, concept coverage, intent-format agreement, and draftable satisfaction criteria — since adjudication, not authoring, is where portfolio throughput scales.
Why keyword research stalls at the brief handoff
Most agency keyword research dies in a spreadsheet. A strategist exports a few thousand terms from Ahrefs or SEMrush, filters by volume and difficulty, color-codes the survivors, and hands the file to a writer with a topic in the subject line. The writer then rebuilds the work the strategist already did: clustering the terms, guessing intent, scanning the SERP, deciding what the article is actually about. That second pass is where cycle time evaporates and where rework loops begin.
The bottleneck is not discovery. Keyword Planner, Trends, and the standard SEO stacks already surface more candidate terms than any content calendar can absorb 7, 3. The bottleneck sits between the term list and a brief a writer can execute without interpretation. Volume-sorted exports do not tell a writer which query the page must satisfy, what language real searchers use, or which SERP type the draft has to compete against.
Google's own guidance reinforces the gap. Search Essentials directs publishers to place the words people actually use in titles and main headings, not the terms that scored highest in a planning tool 2. A brief that hands a writer 40 keywords sorted by volume fails that test before the draft starts. Closing the handoff means treating keyword research as the first stage of brief assembly, not a separate deliverable.
Keyword research as a structured retrieval problem
Borrowing concept decomposition from literature search
Medical librarians solved the keyword problem decades before SEO existed. Faced with the same job agency teams face every week — translate a vague question into a retrieval set that captures what users actually ask without drowning in noise — they built a discipline around concept decomposition. A well-formed question gets broken into its component concepts first, then each concept gets expanded with synonyms, abbreviations, alternative spellings, and variants before any search runs 8.
The transfer to content briefs is direct. A topic like "automated keyword research" is not one keyword. It is at least three concepts stacked together: the activity (research), the modifier (automated), and the output (keywords, or the brief downstream of them). A strategist who skips decomposition and feeds the raw phrase into Keyword Planner gets a volume estimate and a list of look-alikes 7. A strategist who decomposes first gets a structured map of what the article must cover before any tool runs.
NLP-assisted methods now accelerate this work for systematic reviewers, generating candidate term sets from a seed question and surfacing variants a human might miss 9. The same logic compresses brief assembly for content operations: machines expand the concept lattice, strategists prune it.
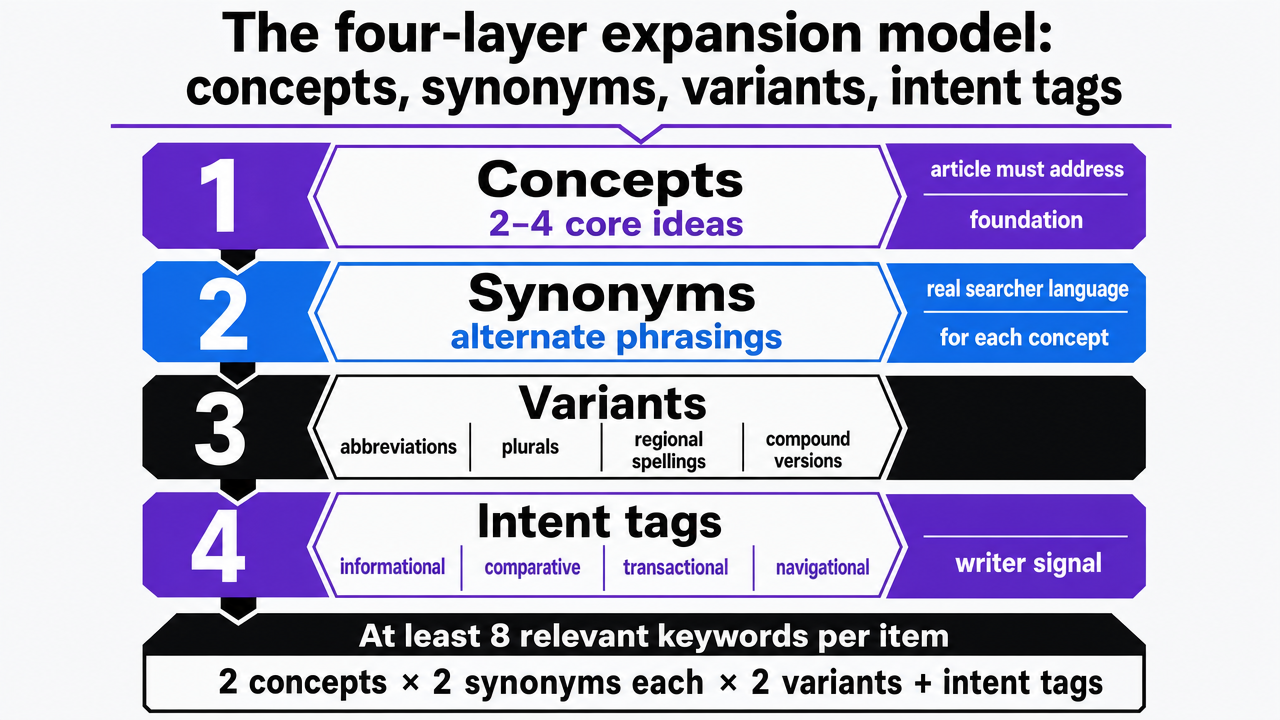
The four-layer expansion model: concepts, synonyms, variants, intent tags
Every brief a writer can execute without rebuilding the research carries four layers of keyword work, not one.
- Concepts come first — the two to four ideas the article must address.
- Synonyms come next — the alternate phrasings real searchers use for each concept.
- Variants follow — abbreviations, plural forms, regional spellings, and compound versions.
- Intent tags close the set — the label that tells the writer whether each term signals informational, comparative, transactional, or navigational behavior.
The biomedical KEYWORDS framework recommends at least eight relevant keywords per item, balancing specificity and generality so the set captures both the precise topic and the broader category a reader might use 10. That floor maps cleanly onto content briefs. Two concepts, two synonyms each, two variants, and two intent-tagged query phrasings put a brief at the eight-keyword minimum without padding the list with near-duplicates.
The literature-search methodology behind the four layers is explicit about why each one matters. Concepts define scope. Synonyms catch the language gap between expert phrasing and audience phrasing. Variants prevent the brief from missing traffic that uses a hyphen, a plural, or an acronym. Intent tags make the brief executable — a writer who sees "automated keyword research [informational, comparative]" knows the page owes the reader both an explanation and a frame for evaluation, not a product pitch 8.
The contrast with a volume-sorted export is the point. A 40-term list ranked by search volume hides the concept structure under a single dimension. A four-layer set, even with eight terms, exposes what the article must cover, in what language, and against what reader expectation. That structure is what survives the handoff to a writer.
 Visualize the four-layer keyword expansion model that structures every brief, directly supporting the section's framework
Visualize the four-layer keyword expansion model that structures every brief, directly supporting the section's framework
Sensitivity and specificity tradeoffs inside a brief
Every keyword set sits on a tradeoff curve. Cast wide and the brief captures more potential queries but risks pulling the article off its core promise. Cast narrow and the brief stays sharp but cedes adjacent traffic to competitors. Literature searchers name this directly: sensitivity (recall — catching everything relevant) versus specificity (precision — excluding the irrelevant) 8.
Inside a brief, the curve shows up as a structural decision the strategist owns. A high-sensitivity brief tells the writer to address several related sub-questions in one page. A high-specificity brief restricts the page to one query type and pushes the others into separate briefs. Neither default is correct. The right setting depends on SERP behavior — whether Google currently rewards a consolidated answer or distinct pages — and on the portfolio strategy for the topic cluster.
The discipline is making the setting explicit in the brief itself. A field labeled "scope: narrow" or "scope: broad" with one line of reasoning prevents the writer from drifting toward whichever interpretation feels easier to draft. It also prevents the next strategist who picks up the topic from re-litigating a decision the keyword research already settled.
Experience Automated Keyword Research in Action Now
Test-drive automated workflows and publish real briefs using live keyword data during your free trial.
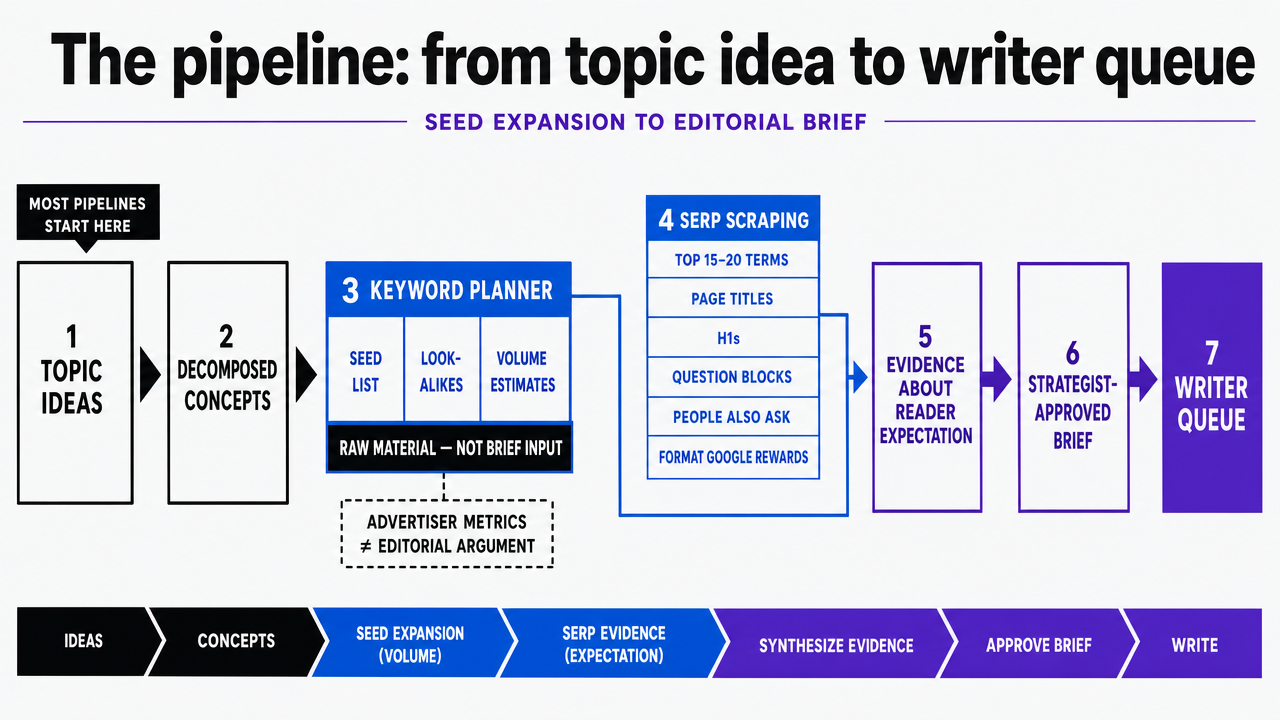
The pipeline: from topic idea to writer queue
Seed expansion with Keyword Planner and SERP scraping
Seed expansion is where most pipelines start and where most of them go wrong. Keyword Planner generates a usable seed list quickly — paste the decomposed concepts, pull the look-alikes, capture the volume estimates 7. The trap is treating that output as a brief input rather than raw material. Keyword Planner's metrics were built for advertisers planning bid budgets, not for editorial teams deciding what a page should argue.
The corrective is pairing Planner output with SERP scraping for the top fifteen to twenty terms in the seed set. The scrape captures what already ranks: page titles, H1s, the question blocks Google surfaces, the People Also Ask chains, and the format Google currently rewards. That layer turns a volume list into evidence about reader expectation, which Search Essentials calls out directly — titles and main headings should carry the words people actually use to look for the content 2.
The output of stage one is not a keyword list. It is a structured table: each seed term mapped to its expansion candidates, current SERP format, top-ranking title language, and a flag for whether the SERP is consolidated or fragmented. Strategists prune from there; writers never see the raw table.
Trend signals: Explore, Top vs Rising, and the Trends API alpha
Trend signals decide which seeds graduate from the candidate table to an active brief. Google Trends Explore caps comparison at five terms at a time, which forces strategists to make explicit choices about what the seed competes against rather than dumping a hundred phrases into a single view 3. That constraint is useful. Five-term batches surface relative momentum cleanly and keep the prioritization decision visible inside the workflow.
The Top versus Rising distinction inside Explore yields two different briefs from the same seed. Top queries show the established phrasings that already drive volume — the language a writer needs in the title and H1 to compete for current demand. Rising queries show breakout terms growing fastest in the period, often before they show up in Keyword Planner's volume estimates 3. A seed like "automated keyword research" pulled through Explore typically branches into a Top-driven brief (defining the category, comparing methodologies) and a Rising-driven brief (covering the specific tool integration or workflow change that spiked recently). The two briefs target different reader moments and should not collapse into one page.
The Trends API alpha changes the operational cost of running this layer at scale. Programmatic access to consistently scaled data, time-range aggregations, and geographic breakdowns means trend signals can feed a brief queue without a strategist clicking through Explore for every seed 4. Alpha status means the dependency is experimental, not production-grade, so teams typically run it alongside the Explore UI rather than replacing manual checks.
Intent tagging and SERP-type classification
Intent tagging is the stage that converts a pruned keyword set into something a writer can act on without guessing. Each surviving term gets one of four labels — informational, comparative, transactional, navigational — based on the SERP behavior the scrape captured in stage one, not on the strategist's intuition about the phrase. The SERP is the arbiter. If Google currently ranks comparison tables and listicles for a term, the intent is comparative regardless of how the phrase reads in isolation.
SERP-type classification runs in parallel. Each term gets tagged with the dominant format Google rewards: definitional article, step-by-step guide, comparison table, product page, video carousel, or a mixed SERP with no clear winner. Mixed SERPs are the most informative signal — they usually mean Google has not settled on a preferred format, which opens room for a brief that combines elements competitors run separately.
The tagging discipline matters because it directly answers Google's instruction to use the words people use to look for the content and put them where they belong 2. A term tagged informational with a definitional SERP belongs in the H1 of an explainer; the same term tagged comparative with a table-dominant SERP belongs in a comparison header. The brief carries the tag, the writer carries the format decision into the draft.
The brief schema: fields every automated output must populate
A brief that survives the writer handoff carries six named fields, populated by the pipeline before a human strategist reviews it. The fields are: primary term, intent tag, concept cluster, synonym set, SERP type, and satisfaction criteria. Each one closes a specific gap that volume-sorted exports leave open.
Primary term : The single phrase the page is engineered to rank for, placed in the title and main heading as Search Essentials specifies 2.
Intent tag : Carries the four-way label from the SERP classification stage, telling the writer what behavior the page must satisfy.
Concept cluster : Lists the two to four ideas the article must address, drawn from the decomposition step.
Synonym set : Carries the alternate phrasings real searchers use — the discoverability literature is explicit that synonyms, lexical variants, and non-redundant terms are what make work findable across the language gap between expert and audience 11.
SERP type : Names the format the page must compete against: definitional, comparative, step-by-step, mixed.
Satisfaction criteria : The field most often missing from automated outputs — names the specific reader questions the page must answer to clear the bar Google sets for content meeting visitor expectations. Without that field, a brief can be technically complete and still produce a draft that loses to a competitor who simply answered the question better.
The schema is what makes automation defensible. Each field traces to a specific input from the pipeline stages above, which means a strategist reviewing the brief is checking populated fields against the evidence rather than reconstructing the research. The brief enters the writer queue as a structured object, not a document a writer has to interpret. That structure is what compresses cycle time without weakening the editorial output.
 Map the end-to-end pipeline stages described across the subsections, showing how raw topic ideas move through automation into a strategist-approved brief
Map the end-to-end pipeline stages described across the subsections, showing how raw topic ideas move through automation into a strategist-approved brief
Helpful-content guardrails built into the pipeline
Where Google's automation warning lands in the workflow
Google's helpful content guidance flags extensive automation used to produce content on many topics as a warning sign, particularly when the output exists primarily to manipulate rankings rather than serve readers 1. The instinct is to read that line as a verdict against automation. The operational reading is narrower: the warning targets pipelines that automate the draft, not pipelines that automate the research feeding a human-edited brief.
The distinction matters because it tells strategists exactly where the guardrail belongs. Seed expansion, synonym generation, SERP scraping, intent tagging, and trend pulls can run without human touch — none of those stages produce reader-facing prose. The pipeline crosses Google's line when automation extends past the brief into the outline, the body copy, or the published page without editorial judgment in between.
Building the guardrail into the workflow means naming the stop point. Automation populates the six brief schema fields; a strategist approves the brief; a writer drafts against it. The approval gate is the artifact that separates a defensible pipeline from the pattern Google's guidance rejects. Without that gate, the same tools that compress cycle time turn into the warning sign.
Satisfaction over coverage at the outline stage
The August 2022 helpful content update reframed the brief outline problem in one line: content that doesn't meet a visitor's expectations won't perform as well 6. Coverage is not the same as satisfaction. A brief that tells a writer to address twelve subtopics because each one has search volume produces a page that touches everything and answers nothing.
The satisfaction criteria field in the brief schema exists to force the tradeoff into the open. A strategist reviewing an automated brief asks a single question of the outline: which reader question does each section close, and which sections exist only because a related term surfaced in the expansion? Sections in the second category get cut, even when the keyword data argues for keeping them.
The discipline shows up in section count, not section length. A brief with four sections that each resolve a distinct reader question outperforms a brief with nine sections that each restate the topic. The outline stage is where coverage instinct has to lose to satisfaction logic.
Accuracy, quality, and relevance as brief acceptance criteria
Google's guidance on AI-assisted content reduces the editorial standard to three words: accuracy, quality, and relevance, with that standard applying with particular force when automation is materially involved in production 5. Read as a brief specification rather than a content review checklist, those three words define what a strategist verifies before a brief enters the writer queue.
- Accuracy is the easiest to operationalize. Every claim the brief instructs the writer to make traces to a named source, or the brief flags the claim for the writer to substantiate.
- Quality lives in the satisfaction criteria — whether the outline actually resolves the question the SERP shows readers asking.
- Relevance ties back to the intent tag and SERP type: a brief targeting a comparative query that outlines a definitional explainer fails the relevance test regardless of how clean the keyword set looks.
The three criteria become acceptance gates, not aspirations. A brief that misses any one of them goes back to the pipeline for a second pass before it ever reaches a writer's calendar.
See How Automated Keyword Research Accelerates Content Brief Turnaround
Request a walkthrough of automated workflows that turn keyword data into actionable briefs—cutting manual research time by over 80% for agency and enterprise teams managing large-scale content programs.
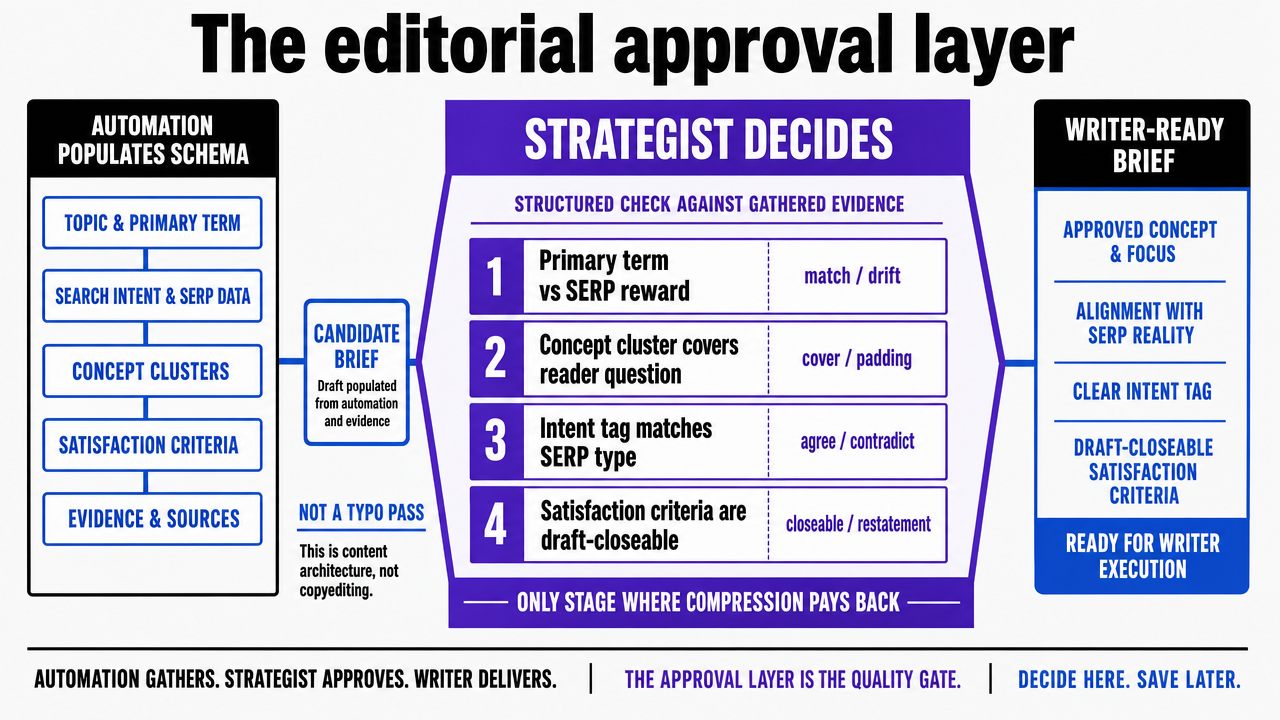
The editorial approval layer
Automation populates the schema. A strategist decides whether the brief ships. That split is what turns a candidate brief into a writer-ready one, and it is the only stage where the pipeline pays back its own compression. Approval is not a final read for typos. It is a structured check against the evidence the pipeline already gathered.
The check runs against four questions, in order.
- Does the primary term match what the SERP rewards, or did the volume signal pull the brief toward a phrase Google currently ranks differently?
- Does the concept cluster cover the reader question without padding from adjacent terms that surfaced in expansion?
- Does the intent tag agree with the SERP-type classification, or do the two fields contradict each other?
- Do the satisfaction criteria name questions a writer can actually close in a draft, or are they restatements of the topic?
A brief that fails any one returns to the pipeline with a flagged field; a brief that clears all four enters the writer queue.
The approval layer also carries the editorial judgment Google's AI-content guidance locates outside the automation itself — accuracy, quality, and relevance as production-time verifications, not post-hoc audits 5. The strategist's job shifts from authoring briefs to adjudicating them. That shift is what makes the throughput gain defensible rather than a warning sign.
 Visualize the four-question approval check that gates briefs before they reach the writer queue, directly supporting the section's structured check
Visualize the four-question approval check that gates briefs before they reach the writer queue, directly supporting the section's structured check
If you run keyword research across a client portfolio
The pipeline described so far assumes a single account. The economics change when the same workflow runs across ten, twenty, or fifty client portfolios at once. At that scale, the cost of the writer-rework loop compounds, and the strategist time spent reconstructing research from scratch for each account becomes the binding constraint on agency throughput.
The consolidation argument is structural. A pipeline that populates six brief schema fields the same way across every account turns research time into a fixed cost per topic rather than a variable cost per client. Strategists stop authoring briefs and start adjudicating them, which is the only configuration where headcount stays flat while brief volume scales 9.
The math is worth making explicit. The variables below carry no assumed dollar values; each agency plugs in its own rates and measures the delta against current state.
| Variable | Manual baseline | Automated pipeline |
|---|---|---|
| Hours per brief (research + assembly) | H_m | H_a |
| Briefs per strategist per week | B_m | B_a |
| Writer rework rate (% drafts returned) | R_m | R_a |
| Cycle time: approved topic to writer queue | C_m (days) | C_a (hours) |
| Accounts per strategist at target quality | A_m | A_a |
A worked example using labeled placeholders: if H_m runs four hours and H_a runs forty-five minutes, a strategist managing twelve accounts with three briefs per account per month recovers roughly 117 hours monthly — the variable to redeploy into approval-layer QA rather than brief authoring. The figure is illustrative; the inputs are what each agency measures against its own baseline.
The constraint Google's guidance imposes on this scaling — that automation feeds editorial judgment rather than replacing it — is what keeps the throughput gain defensible across a portfolio 1. Platforms like Vectoron operate on this split: pipeline-grade research feeding a Command Center where strategists approve briefs against the four-question check, not against blank pages.
Frequently Asked Questions
References
- 1.Creating Helpful, Reliable, People-First Content | Documentation.
- 2.Google Search Essentials (formerly Webmaster Guidelines).
- 3.Get started with Google Trends | Documentation.
- 4.Introducing the Google Trends API (alpha): a new way to access Search Trends data.
- 5.Google Search's Guidance on Generative AI Content on Your Website.
- 6.What creators should know about Google's August 2022 helpful content update.
- 7.Research Keywords for Campaigns with Keyword Planner.
- 8.Back to the basics: guidance for designing good literature searches.
- 9.An automated method for developing search strategies for systematic literature reviews.
- 10.Standardizing Keyword Selection for Improved Big Data Analytics in Biomedical Research: The KEYWORDS Framework.
- 11.Title, abstract and keywords: a practical guide to maximize visibility and impact.
- 12.Keywords, discoverability, and impact.