
Key Takeaways
- Profound delivers scheduled share-of-answer percentages across major engines, making it the cleanest fit for monthly executive decks that need a single defensible number.
- Peec AI prioritizes fast onboarding and white-label multi-workspace structure, suiting agencies that need baseline visibility scores within hours across fifteen to eighty client domains.
- AthenaHQ parses cited URLs and source domains per engine, turning the deliverable into an always-on citation log that supports competitive intelligence work.
- Otterly.AI leads with sentiment and competitor share-of-voice, reframing reporting from isolated brand mentions into category answer share against named competitors.
- Goodie pairs prompt monitoring with draft content briefs, shortening the path from visibility drop to page-level test for agencies with internal content teams.
- Scrunch AI maps entity associations across engines, exposing weak or missing coverage that feeds directly into entity-work deliverables for multi-location brands.
- Vectoron operates as an AEO execution platform, displacing internal production hours by routing entity, schema, and content work through approval workflows tied to tracked visibility metrics.
Client reporting decks now have an AI answers tab
The monthly client review has a new slide. Somewhere between organic sessions and conversion attribution, agency teams are now expected to show how often a brand appears inside answers from ChatGPT, Gemini, Perplexity, Claude, and Google AI Overviews. The slide did not exist eighteen months ago. It is now table stakes for any retainer that includes content or technical SEO.
The pressure is downstream of user behavior. Pew Research found that 65% of U.S. adults at least sometimes encounter AI summaries in search results, and roughly one in five describe those summaries as extremely or very useful 17. That is enough exposure to make AI answer surfaces a brand monitoring problem, not a future-of-search thought piece.
For an agency Head of SEO managing dozens of accounts, the operational question is narrower than the category suggests. Which LLM visibility platform produces a defensible monthly deliverable, supports white-label or multi-workspace structures, and connects to the content pipeline that actually moves the metric? The seven tools that follow are sorted by that job, not by feature parity. The taxonomy comes first because the category label hides three different products doing three different things.
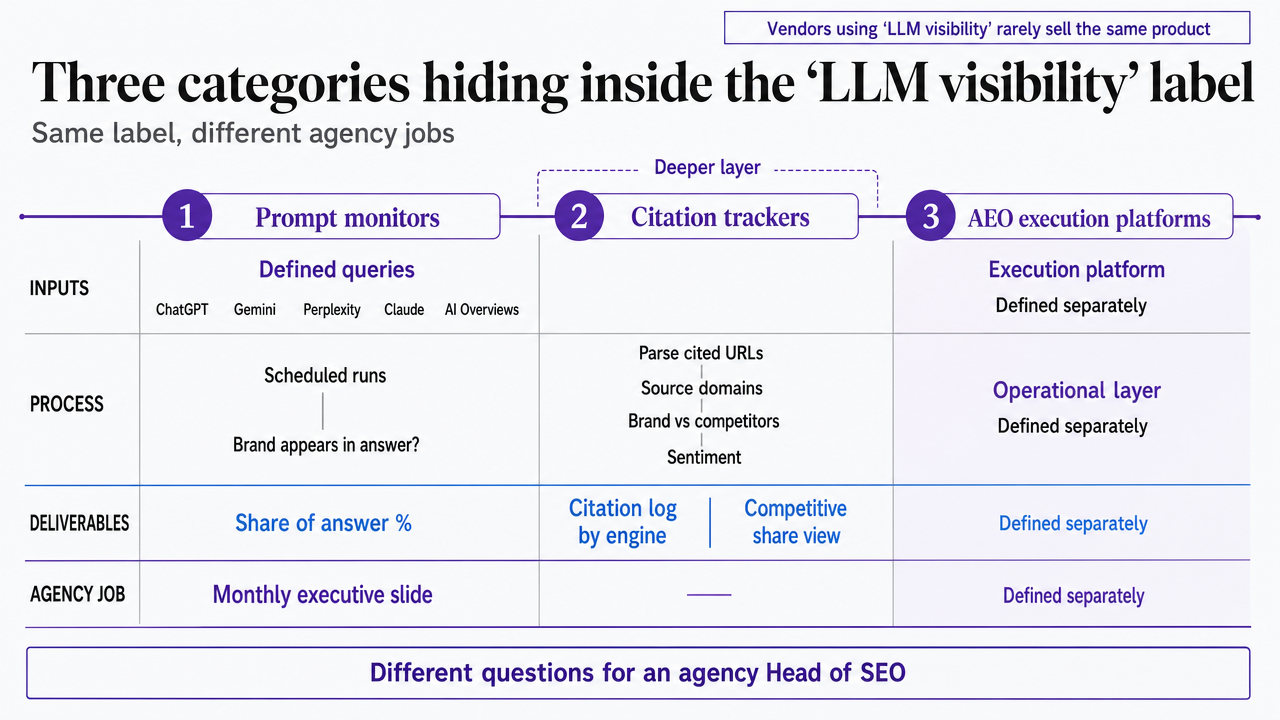
Three categories hiding inside the 'LLM visibility' label
Prompt monitors, citation trackers, and AEO execution platforms
Vendors using the phrase "LLM visibility" rarely sell the same product. Three categories sit underneath the label, and they answer different questions for an agency Head of SEO.
Prompt monitors : Run a defined set of queries against ChatGPT, Gemini, Perplexity, Claude, and AI Overviews on a schedule, then report whether the monitored brand appears in the answer text. The deliverable is a share-of-answer percentage trended over time. The job inside an agency is the monthly executive slide.
Citation trackers : Go a layer deeper. They parse the cited URLs and source domains inside each AI answer, attribute them back to the monitored brand or its competitors, and often layer in sentiment scoring. The deliverable is a citation log per engine plus a competitive share view. The job is the always-on diagnostic dashboard.
AEO execution platforms : Connect measurement to production. They take the same prompt-set and citation signals and feed them into entity work, content briefs, schema updates, and publishing workflows. The deliverable is finished optimization work tied to a visibility metric. The job is closing the loop between what is measured and what gets shipped.
The five-pillar framework for LLM search visibility — entity work, answer clusters, secondary sources, content structure, and AI-specific measurement — clarifies why no single category covers everything 8. Prompt monitors touch pillar five only. Citation trackers extend into pillars three and four. Execution platforms operate across all five.
Why the category matters more than the feature list
Feature checklists flatten the buying decision. Two tools can both claim "multi-engine citation tracking," yet one runs a fixed synthetic prompt set against four engines weekly while the other ingests harvested organic keywords and live user-submitted prompts daily 7. The marketing copy looks identical. The reporting fidelity does not.
For an agency, the category determines three things that feature lists do not:
- the cadence of the deliverable,
- the seat structure on the price card, and
- whether the tool plugs into the content production pipeline that actually moves citation frequency by platform and visibility scores across engines 8.
A prompt monitor billed per workspace can support a fifteen-client portfolio cleanly. A citation tracker billed per domain rewards consolidated reporting but penalizes franchise rollups. An execution platform displaces internal production hours, which changes the retainer math, not just the software line item.
Mapping each vendor below to one of the three categories before reading its entry prevents apples-to-oranges comparison and surfaces what each tool is actually built to do.
 Visualize the three distinct tool categories described in the section (prompt monitors, citation trackers, AEO execution platforms) and the job each performs inside an agency, since this section explicitly defines a comparison framework
Visualize the three distinct tool categories described in the section (prompt monitors, citation trackers, AEO execution platforms) and the job each performs inside an agency, since this section explicitly defines a comparison framework
What measurement methodology actually decides
Prompt fidelity: synthetic, harvested, or user-submitted
Prompt sets are where most visibility tools quietly diverge. A vendor offering "5,000 prompts per workspace" is not making the same product as one offering "500 harvested queries plus live user-submitted prompts." The number is not the variable. The provenance is.
Three sourcing methods dominate the category 7:
- Synthetic prompts are generated by an LLM from a seed topic list, which produces volume cheaply but drifts from how real users phrase questions.
- Harvested prompts pull from the client's existing organic keyword data and reformat queries into conversational shape, anchoring the set to demonstrated demand.
- User-submitted prompts come from the client's own sales, support, and CRM logs and capture the long-tail phrasing that synthetic generation misses.
For agency reporting, the practical implication is that synthetic-only tools produce share-of-answer numbers that move based on prompt-set assumptions, not on actual content performance. SEO leads auditing a vendor should ask for the prompt provenance ratio before comparing the scores it returns.
LLM-as-a-judge scoring and its known biases
Citation accuracy and sentiment do not score themselves. Most visibility platforms run a judge model — a second LLM — that reads each answer and rates whether the brand was mentioned correctly, in what context, and with what tone. The technique is borrowed directly from RAG evaluation, where LLM-as-a-judge has become the default automated scoring method for relevance, faithfulness, and context quality 14.
The borrowing comes with the original method's known weaknesses. Judge models exhibit position bias, verbosity bias, and self-preference when scoring outputs from the same model family they belong to 15. They can also miss subtle negative framing or conflate brand mentions with competitor mentions when names appear in the same paragraph. The recommended fix in the RAG literature is to pair LLM judges with gold-standard human-labeled samples and adversarial security tests 15, a step most visibility vendors do not surface in their methodology pages.
An agency reselling these scores should know which judge model is being used and how often it is calibrated against human review.
Lab gains vs. live engines
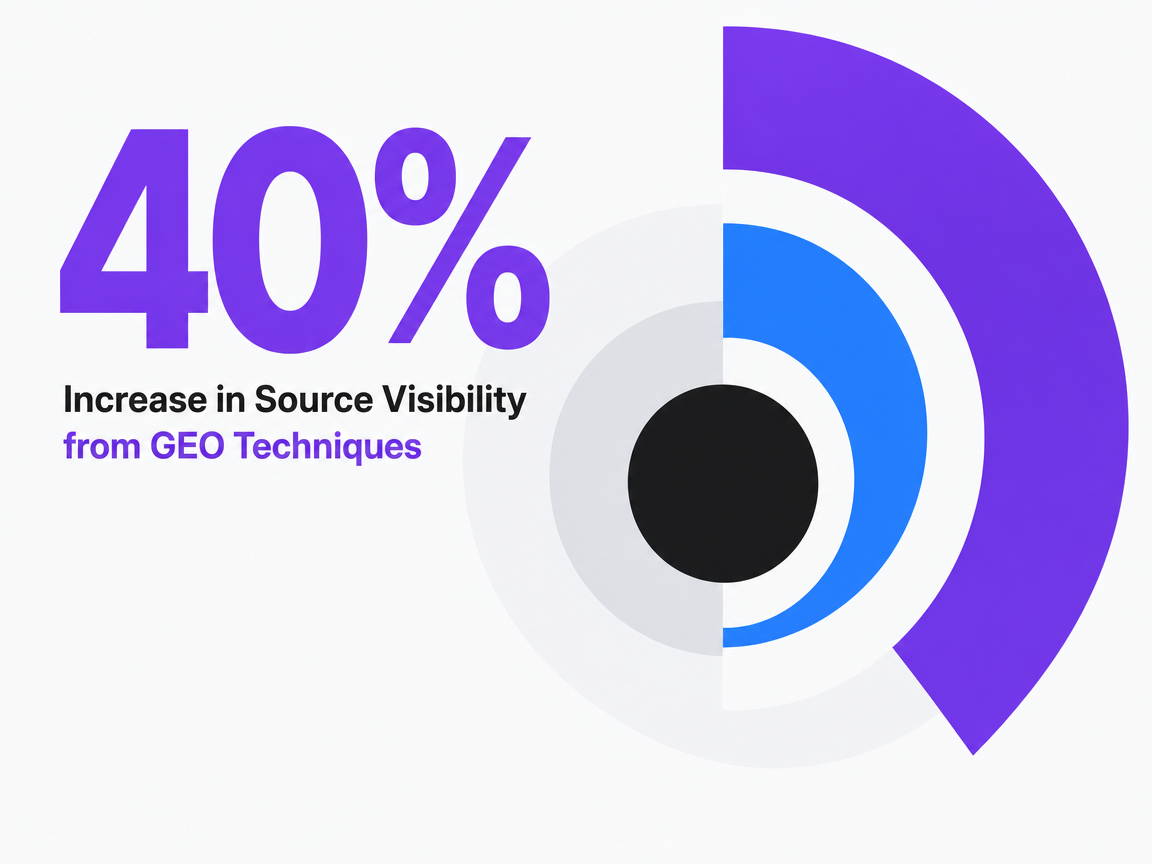
The most-cited statistic in the AEO category needs scope language attached to it. The foundational GEO paper reported that adding citations, quotations from relevant sources, and statistics to content increased source visibility in generative engines by up to 40% across the tested query set 5. The figure has since become shorthand for what AEO can deliver. A critical review of the same paper notes that those 30–40% gains occurred inside a constrained experimental environment, with specific model configurations and prompt designs that do not map cleanly to live ChatGPT, Gemini, Perplexity, or AI Overviews behavior 6.
The practical reading for an agency: directional, not absolute. Visibility tools that benchmark client uplift against a 40% target are extrapolating beyond what the source claims. The defensible deliverable is a client-specific baseline, a documented prompt set, and a tracked delta over time — not a vendor-supplied uplift figure borrowed from a lab.
 Increase in Source Visibility from GEO Techniques
Increase in Source Visibility from GEO Techniques
Increase in Source Visibility from GEO Techniques
Run Real LLM Visibility Audits in One Week
Test live LLM visibility checks and publish actionable insights on actual client domains during your trial.
The seven tools, sorted by the job they do inside an agency
Profound — prompt monitor for executive-facing share-of-answer reports
Profound sits in the prompt monitor category and earns its slot because the output format maps directly onto a monthly client deck. The platform runs scheduled prompt sets against ChatGPT, Gemini, Perplexity, and Claude, returns a share-of-answer percentage per engine, and trends the figure over weeks. For an SEO lead presenting to a CMO who does not want to read citation logs, that single chart is the deliverable.
The job-to-be-done is executive narrative. Profound's prompt library leans synthetic by default, generated from seed topics rather than harvested keywords, which keeps onboarding fast but introduces the provenance question flagged earlier 7. Agencies running it as a reporting layer typically supplement the default set with client-supplied prompts from sales and support logs.
Where it stops short: the tool reports the score but does not parse cited source URLs at the depth a competitive diagnostic requires, and it does not feed signals into content production. The output is a number to defend, not a brief to ship. For agencies billing AEO as a retainer add-on with a fixed monthly report, that is sufficient. For agencies expected to move the number, it is the first layer of a deeper stack.
Peec AI — prompt monitor built for fast client onboarding
Peec AI competes on time-to-first-report. The platform's onboarding flow accepts a domain, generates an initial prompt set from inferred topic clusters, and produces a baseline visibility score across ChatGPT, Perplexity, Gemini, and AI Overviews within hours. For agencies onboarding a new client into an AEO add-on mid-retainer, that speed compresses the sales-to-deliverable gap.
Inside the category, Peec AI's distinguishing trait is workspace structure. Multi-client accounts are first-class, and reporting can be white-labeled per workspace, which matters for agencies running fifteen to eighty client domains under one master account. The tradeoff is depth: the default prompt set skews synthetic, and citation parsing is shallower than dedicated trackers like AthenaHQ or Scrunch AI.
Limitations track the category. Sentiment scoring exists but relies on LLM-as-a-judge methodology without disclosed calibration against human-labeled samples, which carries the verbosity and self-preference biases documented in the RAG evaluation literature 15. For agencies, the right framing is that Peec AI handles the reporting cadence well and leaves diagnostic depth and production execution to other tools in the stack.
AthenaHQ — citation tracker focused on multi-engine attribution
AthenaHQ shifts the deliverable from share-of-answer to citation log. The platform parses each AI answer, extracts the cited URLs and source domains, and attributes them back to the monitored brand, its competitors, and the broader publisher set feeding each engine. Output is structured as a citation database with per-engine, per-prompt, per-day granularity.
That format changes what the agency can sell. Instead of a monthly slide, AthenaHQ supports an always-on dashboard surfacing which third-party domains are feeding the client's category answers across ChatGPT, Gemini, Perplexity, and AI Overviews. Since these engines select sources based on overlapping trust, structure, relevance, and freshness signals 9, a citation log exposes the secondary-source pillar of the visibility framework 8in a way prompt monitors do not.
The methodology question stays relevant. AthenaHQ uses a judge model for sentiment and contextual accuracy, and the same biases apply 14, 15. The platform exposes the judge model configuration in its documentation, which is more than most competitors offer. For agencies pitching competitive intelligence as part of the AEO retainer, the citation log is the artifact that justifies the line item. The limitation: it diagnoses without prescribing, which keeps execution on the agency's side of the wall.
Otterly.AI — citation tracker for sentiment and competitor share
Otterly.AI overlaps with AthenaHQ on citation parsing but leads with sentiment and competitor share-of-voice as the primary outputs. The platform tracks brand mentions across ChatGPT, Perplexity, Gemini, Claude, and AI Overviews, then categorizes each mention as positive, neutral, or negative and benchmarks volume against named competitors. For agencies with retainers that include reputation monitoring, that overlay is the operational draw.
The competitor-share view is where Otterly.AI earns a place in the stack. Most prompt monitors report client visibility in isolation. Otterly.AI reports it as a percentage of the named competitive set per engine, which converts the deliverable from "we are mentioned X% of the time" into "we hold Y% of the category answer share against competitors A, B, and C." That framing survives an executive review better than absolute numbers.
Sentiment scoring carries the same LLM-as-a-judge caveats covered earlier 15, and Otterly.AI does not publicly document human-calibration cadence. Agencies reselling sentiment metrics should disclose the methodology limitation in their client documentation rather than present scores as ground truth.
Goodie — prompt monitor with content brief outputs
Goodie occupies a middle position in the taxonomy. It runs prompt sets against the major engines like a standard monitor, but the output layer includes draft content briefs flagging which entities, answer clusters, and structural patterns are missing from the client's existing pages. The bridge to production is one step shorter than pure monitors offer.
For agencies with internal content teams, that handoff matters. Goodie's briefs are not finished work, but they shorten the path from "visibility dropped on these prompts" to "here is the page-level change to test." The platform leans on the secondary-source and content-structure pillars of the LLM visibility framework 8when generating recommendations, which aligns the brief output with what AI Overviews and Copilot actually weigh during source selection 9.
The limitation is execution capacity. Briefs still require writers, editors, and publishing workflows to ship. Goodie measures and recommends; the agency's production stack moves the metric. For teams already at content-team capacity, the briefs become a backlog rather than a throughput gain.
Scrunch AI — citation tracker with entity coverage diagnostics
Scrunch AI's distinguishing layer is entity coverage. Beyond parsing cited URLs, the platform maps which entities — products, services, locations, people, concepts — are associated with the client brand inside AI answers and which entity associations belong to competitors. For agencies running entity work as a deliverable, that map is the diagnostic input.
The platform addresses the entity-work pillar of the visibility framework directly 8, an area most citation trackers treat as out of scope. Scrunch AI exposes which entity associations are weak or missing across ChatGPT, Gemini, Perplexity, and AI Overviews, then trends coverage over time as schema, content, and knowledge-graph signals change. For multi-location service brands where each location is an entity, the per-location coverage view is the operational artifact.
What it does not do: produce the schema, content, or knowledge-graph updates that close the gaps it identifies. Diagnostic depth is high; execution is still the agency's job. For agency Heads of SEO with strong internal entity-work capacity, Scrunch AI is the diagnostic feeder. For those without, the gap list becomes another backlog.
Vectoron — AEO execution platform that closes the loop into production
The seventh entry sits in a different category from the first six. Where prompt monitors and citation trackers stop at measurement and recommendation, an AEO execution platform extends into production: entity updates, schema changes, content briefs, drafted pages, and publishing workflows tied to the same visibility signals the monitoring layer surfaces. The deliverable is finished optimization work attributed to a tracked metric, not a report defending a number.
That category matters for agencies because the constraint at scale is rarely measurement. It is production capacity. Visibility tools surface gaps faster than internal content teams can ship fixes, and the backlog absorbs the gains. An execution platform displaces internal hours across the five visibility pillars 8— entity work, answer clusters, secondary sources, content structure, and AI-specific measurement — and routes each output through human approval before publishing, which preserves the editorial control agencies require for client work.
The relevant evaluation criteria shift from prompt fidelity and citation depth to approval workflow design, output quality at scale, and integration with existing content operations. For an agency Head of SEO weighing whether to add headcount or add platform capacity, the execution-layer option changes the retainer math directly. Vectoron is the execution-layer entry in this category.
Agency economics: how each category lands on the P&L
The choice between the three categories shows up on the agency P&L in three different places:
- Prompt monitors land as a per-workspace software line on the retainer add-on, billed alongside rank tracking.
- Citation trackers usually price per domain or per tracked competitor set, which rewards depth on fewer accounts and penalizes wide portfolio rollups.
- AEO execution platforms displace internal production hours, which moves the cost out of software and into headcount avoidance.
The shape of each cost structure matters more than the absolute number, which varies by vendor and contract terms. The table below describes the patterns publicly observable across the category, with cost ranges left as variables agencies should source directly from vendors during procurement.
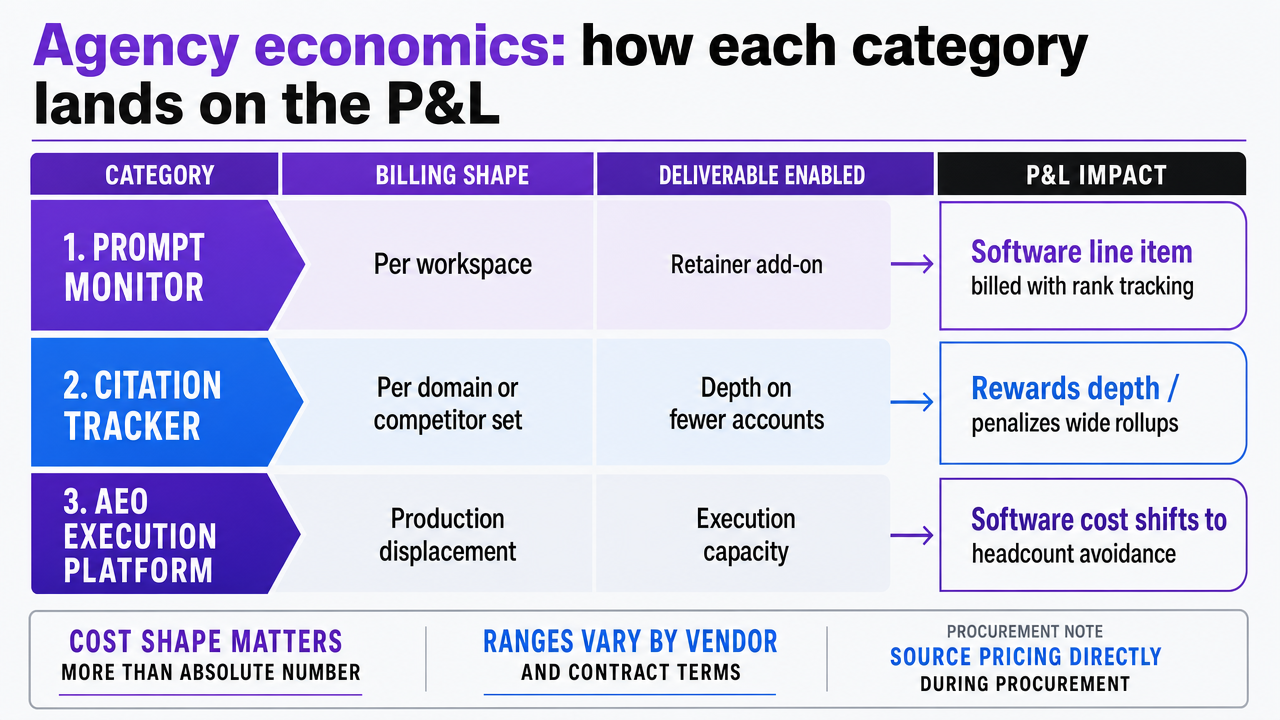
| Category | Billing shape | Deliverable enabled | P&L impact |
|---|---|---|---|
| Prompt monitor | Per workspace, flat tier | Monthly visibility report | Software line on retainer add-on |
| Citation tracker | Per domain or per competitor set | Always-on diagnostic dashboard | Software line plus analyst hours |
| AEO execution platform | Per workspace or platform flat fee | Production-integrated optimization | Displaces internal content and entity-work hours |
For an agency Head of SEO running fifteen to eighty accounts, the relevant math is billable-hour displacement, not software cost. A citation tracker that surfaces gaps faster than the production team can ship fixes converts into backlog, not revenue. Pricing the AEO retainer requires matching tool category to the agency's actual production capacity, because optimization signals for one engine often carry across ChatGPT, Claude, Perplexity, Gemini, and AI Overviews 11, and the throughput constraint is what determines whether the retainer scales.
 Render the comparison table from the section as a structured visual so readers can quickly scan billing shape, deliverable, and P&L impact across the three tool categories
Render the comparison table from the section as a structured visual so readers can quickly scan billing shape, deliverable, and P&L impact across the three tool categories
See How Enterprise Teams Benchmark LLM Visibility at Scale
Request a walkthrough of advanced LLM visibility reporting workflows—learn how leading agencies automate monitoring, surface ranking gaps, and coordinate rapid content updates across large client portfolios.
What these tools cannot do
Every platform in the list above shares a ceiling. Measurement surfaces the gap; it does not close it. A citation tracker can show that a competitor owns 60% of the answer share on a high-intent prompt cluster, and a prompt monitor can trend that gap weekly, but neither writes the page, updates the schema, builds the entity associations, or earns the secondary-source citations that move the metric. Those moves happen in the content production pipeline.
The point matters because AI Overviews and Copilot select sources based on trust, content structure, query relevance, and freshness signals 9, and Google's own guidance reinforces that the work is sound technical SEO and people-first content rather than measurement instrumentation 1. Tools that score those signals do not produce them. For an agency Head of SEO, the practical consequence is that adding a measurement layer without expanding production capacity converts visibility insights into a backlog. The number gets watched; it does not get moved.
Picking the stack that matches the retainer
The selection rule is narrower than vendor demos suggest. Match the tool category to the deliverable the retainer already bills for, then verify the prompt provenance and judge-model methodology before signing.
- Agencies selling a monthly AEO report should anchor on a prompt monitor with multi-workspace structure.
- Agencies selling competitive intelligence or always-on diagnostics should anchor on a citation tracker with documented entity coverage.
- Agencies selling outcomes — visibility lift attributed to shipped work — need an execution layer, because measurement without throughput converts insight into backlog.
The cross-engine overlap softens the stack decision: optimization signals that move ChatGPT often carry across Claude, Perplexity, Gemini, and AI Overviews 11, so a single well-instrumented prompt set and a production pipeline that ships against it tend to outperform a wider monitoring footprint with no execution capacity behind it. Pick the category the retainer can act on. Vectoron sits in the execution layer for agencies sizing that gap.
Frequently Asked Questions
References
- 1.Optimizing your website for generative AI features on Google Search.
- 2.Large Language Model Optimization (LLMO) explained.
- 3.Answer Engine Optimization (AEO): What It Is and How It Works.
- 4.Optimizing Content for Generative Search Resulted in +40% Visibility.
- 5.GEO: Generative Engine Optimization.
- 6.Generative Engine Optimization Paper: A Critical Review.
- 7.Ultimate Guide to LLM Tracking and Visibility Tools 2026.
- 8.What Really Drives LLM Search Visibility?.
- 9.How Google AI Overview & Bing Copilot Choose Sources - Egnoto.
- 10.Optimizing Your SEO for Google AI Overviews - Bee Partners.
- 11.Boost AI Visibility: Rank on ChatGPT, Claude & Perplexity.
- 12.LLMO / Generative Engine Optimization (GEO): How do you optimize for the answers of generative AI systems?.
- 13.Answer Engine Optimization: AEO Strategies vs. Traditional SEO.
- 14.What is RAG evaluation? Measuring retrieval quality and answer relevance.
- 15.RAG Evaluation Metrics: Best Practices for Evaluating RAG Systems.
- 16.GEO: Generative Engine Optimization.
- 17.Americans have mixed feelings about AI summaries in search results.