
Key Takeaways
- Enterprise blogs now operate as three-layer systems: a decision-anchored topic architecture, a governed production workflow with human sign-off, and measurement that reports in pipeline dollars rather than sessions.
- The 39-point gap between enterprises creating thought leadership and those running it as a formal program is where governance, originality gates, and repeatable workflows separate compounding blogs from stalled ones 8.
- Classify the blog as long-cycle demand creation, retire last-click for multi-touch attribution and marketing mix modeling, and use governance-based reporting to absorb core update volatility instead of transmitting it 11, 12.
- Install the layers in a 90-day sequence: architecture and originality gates in month one, approval-first workflow and AI provenance in month two, then multi-touch and MMM measurement in month three 1, 4.
What Changed in 2026: From Publishing Calendars to Operating Systems
The enterprise SEO blog stopped being a publishing schedule the moment ranking volatility outpaced editorial planning. Google's May 2026 core update ran from May 21 through June 2, reshuffling result pages across a twelve-day window and leaving content teams to explain quarterly traffic swings they did not cause 3. Volatility on that timescale breaks any operating model that treats the blog as a calendar of assets to ship.
What replaced the calendar is closer to an operating system. Three layers now decide whether a blog compounds pipeline or leaks budget:
- a topic architecture tied to buying decisions,
- a governed production workflow with human sign-off on every asset, and
- a measurement stack that reports content impact in pipeline dollars rather than sessions.
Each layer answers a question the calendar model could not. Which topics deserve investment. Who approved this asset and on what evidence. What did content contribute to closed revenue.
The pressure to formalize these layers is not theoretical. Google's helpful content guidance, updated in December 2025, sharpened its language on originality and AI-assisted disclosure, warning against content produced primarily to rank rather than to serve readers 1. The same guidance that penalizes volume-first playbooks also rewards depth, authorship, and comprehensiveness. That reward structure favors teams with governance, not teams with the biggest editorial calendar.
The reader running an in-house function already knows the tactical vocabulary. What has changed is that the tactics no longer add up to a program without an operating model behind them. The rest of this piece unpacks the three layers, the execution gap most enterprise teams still carry into 2026, and a 90-day sequence for standing the system up without expanding headcount.
The Execution Gap Inside Enterprise Content Teams
The gap between what enterprise content teams say they do and what they actually run as a program is the single clearest predictor of whether an SEO blog compounds pipeline. CMI's 2026 enterprise research surveyed marketers at organizations with 1,000 or more employees and found that 94% create thought leadership content, while only 55% report having a formal program in place 8. The 39-point gap is the story. Nearly every enterprise ships thought leadership. Barely half operate it as a governed program with defined ownership, editorial standards, and measurement.
That distinction matters because search systems increasingly reward the second group. Google's helpful content guidance asks whether an article demonstrates first-hand expertise, original analysis, and a clear reason to exist beyond ranking 1. Ad hoc thought leadership rarely clears that bar at scale. Program-run content does, because governance forces the questions that ad hoc production skips: who is the named author, what evidence supports the central claim, what has changed since the last piece on this topic, and how is this asset different from three competitors already ranking.
The execution gap also shows up in operating economics. Teams without a program treat each blog post as a project, which means every asset carries fresh briefing, alignment, and review overhead. Teams with a program treat posts as instances of a repeatable workflow, which is where the cost curve bends. The same headcount produces more publishable, defensible assets because the decisions that consume time — angle, evidence, author, structured data, distribution — are made once at the program level rather than re-litigated per post.
Closing the gap does not require more writers. It requires the three layers the rest of this piece unpacks: a topic architecture that decides what deserves investment, a workflow that decides who approves what and on what evidence, and a measurement stack that reports impact in terms a CFO recognizes. Enterprises already producing thought leadership have the raw material. The 39-point gap between creation and program is where the operating model gets installed.
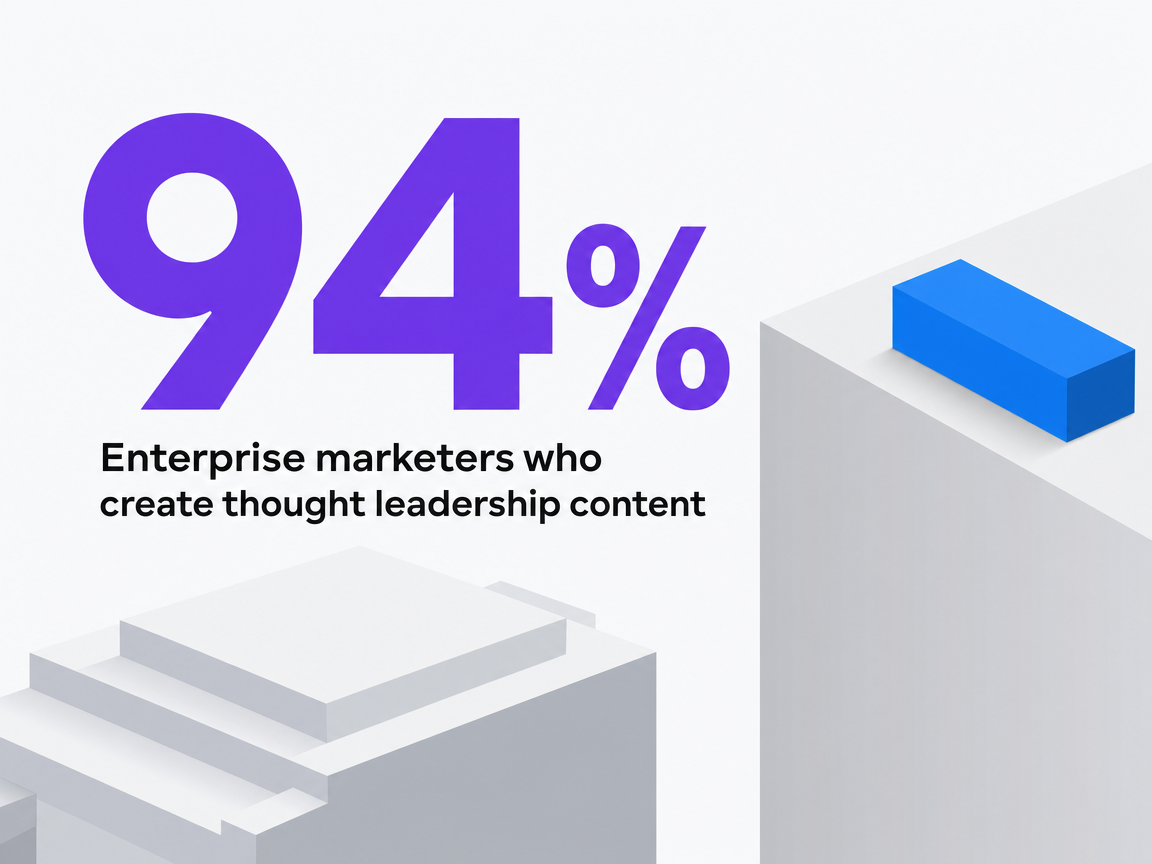 Enterprise marketers who create thought leadership content
Enterprise marketers who create thought leadership content
Enterprise marketers who create thought leadership content
Test Enterprise SEO Blog Execution on Live Content
Experience a real-world workflow by publishing and measuring SEO blog content outcomes during your trial period.
Layer One: Topic Architecture Tied to Buying Decisions
Topic architecture is the layer where most enterprise blogs quietly fail. The failure mode is not a missing keyword or a thin cluster. It is a taxonomy built around search volume and topical adjacency rather than the decisions buyers actually make. When clusters map to volume, the blog produces traffic that never crosses into a sales conversation. When they map to buying decisions, every asset has a defined role in a revenue path and a defensible reason to exist under Google's originality bar.
Mapping Clusters to Revenue-Bearing Decisions, Not Search Volume
A revenue-bearing decision is any moment where a prospect commits to, rejects, or defers a purchase-relevant choice. Building versus buying. Consolidating vendors. Replacing an incumbent tool. Adding a new practice area or service line. These decisions carry keyword footprints, but the footprint is a symptom of the decision, not the decision itself. Volume-first architectures invert that relationship and end up with clusters that rank for queries no buyer performs on the path to a contract.
The practical shift is to anchor each cluster to a decision, then work outward to the queries that decision generates across research, evaluation, and validation stages. A cluster on multi-vendor consolidation, for example, produces different assets at different depths: a strategic case for consolidation, a comparison framework for evaluating candidates, a risk register for the transition, and a set of validation pieces addressing objections a procurement team will raise. Each asset serves one decision from a distinct angle.
This is the same reframing Google's own measurement guidance pushes on marketers, which emphasizes assembling a full picture of customer interactions rather than optimizing for isolated touchpoints 11. Applied to topic architecture, it means the blog's job is to be present at each interaction a decision requires, not to accumulate rankings against every adjacent term. Clusters organized this way also generate cleaner attribution signals, because each asset is tagged to a known decision stage rather than a query bucket.
Originality Standards Under Google's Helpful Content Guidance
Google's helpful content guidance sets an originality bar most enterprise blogs still write below. The guidance asks whether a page provides original information, reporting, research, or analysis; whether it offers substantial value compared to other pages in the results; and whether it was produced primarily to help readers rather than to attract search visits 1. Those three tests function as an editorial standard, not a checklist. They decide what the topic architecture is allowed to publish under each cluster.
Operationally, this means each planned asset needs a defined source of originality before it enters production:
- Proprietary data from the company's own operations.
- First-hand analysis from a named subject-matter expert.
- A synthesis of primary sources that no ranking competitor has assembled.
- A point of view that takes a defensible position rather than aggregating consensus.
Assets that cannot name their source of originality at planning time should be cut from the calendar, not sent to a writer to figure out.
The December 2025 update to Google's guidance sharpened this test further, adding clearer language on AI-assisted content and the expectation that automation be disclosed and directed toward reader value rather than ranking volume 1. For a topic architecture, the consequence is straightforward: originality is a per-asset gate before scale, not a quality-assurance step after drafts exist.
Structured Data as an Architectural Discipline
Structured data belongs at the architecture layer, not the publishing checklist. Treated as a checklist item, schema gets bolted onto assets after the fact and rarely reflects the decision each asset actually serves. Treated as an architectural discipline, schema is decided at cluster design: which asset types map to Article, FAQPage, HowTo, Product, or Organization markup, and how those types reinforce the decision path the cluster is built around.
The operational control point is validation. Google's Rich Results Test checks whether a publicly accessible page supports rich results based on its structured data, and it belongs in the pre-publish gate for every asset that carries schema 2. Assets that fail validation do not ship. That single rule keeps the architecture honest, because it forces the team to model schema against real asset types rather than aspirational ones.
Schema decisions made at the architecture layer also compound over time. Consistent author markup builds identifiable expertise signals across a cluster. Consistent FAQPage markup on validation-stage assets makes the blog answerable in features designed for that intent. The discipline is upstream design, not downstream tagging.
Layer Two: A Governed Production Workflow
Architecture decides what deserves investment. Workflow decides whether the assets actually get built to standard, on cadence, and with a defensible record of who approved what. The second layer is where most enterprise blogs still run on habit rather than governance, which is why output stalls the moment a senior editor takes leave or a strategist rotates off the account.
The Approval-First Loop: Signal, Recommendation, Human Sign-Off, Execution
A governed workflow reduces to four stages that repeat per asset: signal intake, recommendation, human sign-off, and execution with measurement feedback. NIST's AI Risk Management Framework is designed to be applied voluntarily to improve how trustworthiness considerations are incorporated into AI systems, and its governance principles map cleanly onto content operations that mix human editorial judgment with automation 4. The loop is the operational expression of those principles.
- Signal intake is the raw material. Ranking shifts, competitor coverage changes, sales-call transcripts, product releases, and analytics anomalies all count as signals. The workflow's first job is to normalize them into a queue rather than react to whichever one landed in a Slack channel that morning. Without a queue, the blog inherits whoever shouted loudest that week.
- Recommendation converts signals into proposed assets with a defined angle, evidence source, author, and target decision stage. This is the stage where AI assistance earns its keep, because pattern recognition across signals scales faster than a strategist reading each one manually. The output is not a draft. It is a proposal with reasoning attached.
- Human sign-off is the non-negotiable gate. A named editor or strategist approves the recommendation before any production work begins, and that approval is recorded against the asset for the life of the program. This is what keeps governance auditable when a core update forces a retrospective on what shipped and why.
- Execution follows approval, and measurement feedback closes the loop by writing performance data back against the original recommendation. The next signal intake cycle inherits that data. The loop compounds because it learns, not because it publishes more.
AI-Assisted Production, Provenance, and Disclosure Controls
AI assistance inside the workflow is not the risk. Undocumented AI assistance is. Google's helpful content guidance was updated in December 2025 with sharper language on AI-generated and AI-assisted content, keeping the focus on whether the output serves readers rather than whether a machine touched it 1. The operational consequence is that provenance needs to be tracked per asset, not per program.
Three controls carry the weight:
- Provenance tracking. Every asset records which stages used AI assistance, at what depth, and against which prompts or model versions. This is the audit trail a governance review requires, and it aligns with the NIST AI RMF emphasis on documented, trustworthy use of AI systems 4.
- Named human authors. Named human authors are attached to every published piece and remain accountable for the claims inside it. Anonymous or byline-free assets fail the originality tests Google's guidance sets out 1.
- Program-level disclosure defaults. Disclosure is handled at the program level rather than negotiated per post. When blog content gets repurposed into sponsored placements, executive-authored social posts, or partner distribution, FTC guidance requires that promotional intent be clearly identifiable and that material relationships be obvious to the audience 5, 6. Building those disclosure defaults into the workflow prevents the compliance scramble that hits every enterprise the first time a piece of blog content crosses into paid distribution without the right label.
Retainer Economics vs. a Governed In-House Workflow
The economics comparison is less about hourly rates than about where decisions live. Traditional agency retainers price the briefing cycle, the account-management layer, the review rounds, and the per-asset production time as a bundle. Every new post re-enters that bundle, which is why per-asset costs stay flat even after a team has published on the same topic cluster twenty times. The learning does not compound inside the invoice.
A governed in-house workflow bends the curve because the decisions that consume time — angle, evidence, author, structured data, disclosure defaults — get made once at the program level and reused per asset. Headcount does not have to grow to add throughput, which is the specific pressure most VPs of Marketing are under heading into 2026. Google's own guidance on profitable growth points in the same direction, arguing that AI in marketing, disciplined measurement, and customer understanding are what allow teams to scale without proportional cost increases 14.
Platforms that operationalize the approval-first loop, including Vectoron's AI marketing team platform available on a two-week trial at $599 per month, exist to install that curve-bending layer without an agency contract. The point is not the tool. The point is that the workflow, not the writer count, decides whether the blog compounds.
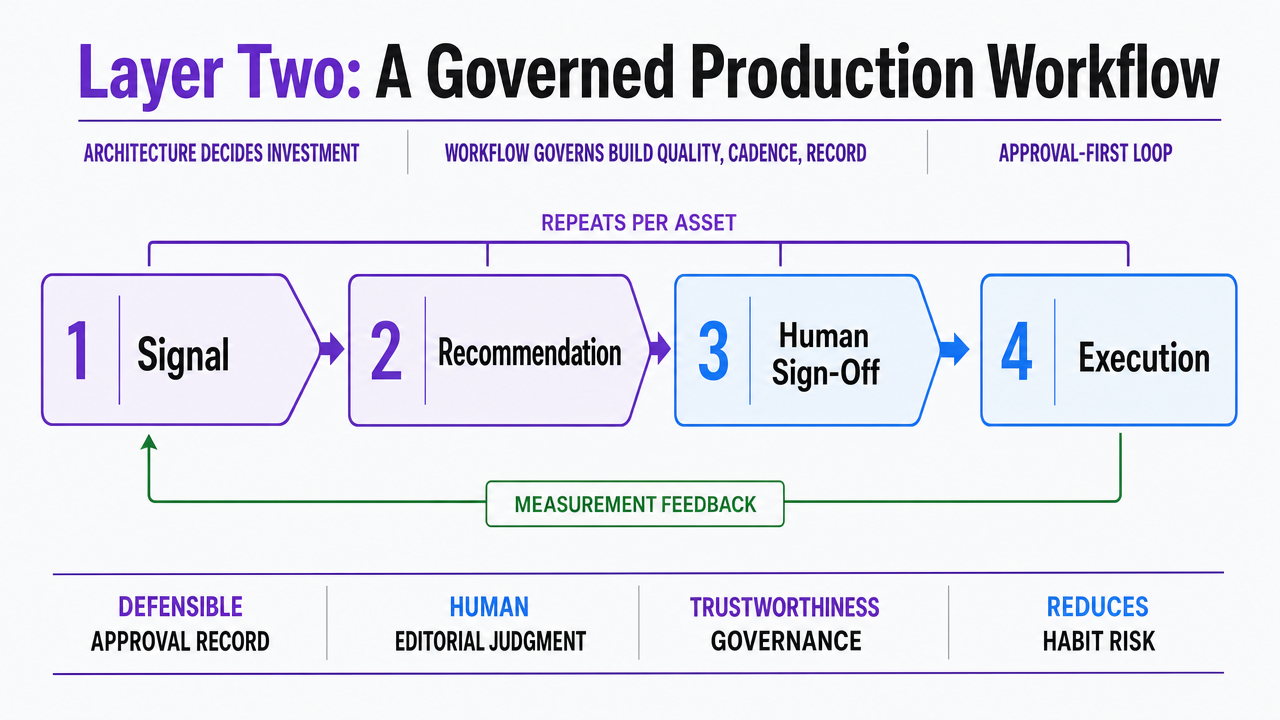 Visualize the four-stage approval-first loop (signal, recommendation, human sign-off, execution) explicitly described in the section as the governed workflow
Visualize the four-stage approval-first loop (signal, recommendation, human sign-off, execution) explicitly described in the section as the governed workflow
See How Leading Enterprises Streamline SEO Blog Execution at Scale
Connect with our team to benchmark your current content operations against data-driven models for predictable SEO growth—purpose-built for in-house marketing leaders managing enterprise or multi-location brands.
Layer Three: Measurement That a CFO Will Accept
The measurement layer is where enterprise SEO blogs either earn their budget line or lose it during the next planning cycle. Rankings and sessions do not answer the question a CFO actually asks, which is what the blog contributed to pipeline and closed revenue. The third layer replaces surface metrics with a measurement stack that connects content investment to business outcomes across long time horizons and multiple touchpoints.
Retiring Last-Click for Multi-Touch and Marketing Mix Modeling
Last-click attribution systematically understates blog contribution because the assets that shape a buying decision rarely sit in the final session before conversion. A prospect reads a strategic case for consolidation in March, returns for a comparison framework in May, and converts on a branded search in July. Last-click credits the branded search and hides everything upstream. The blog looks like overhead on the report even when it did the work.
Google's own measurement guidance argues that marketers need a strategy showing a full picture of customer interactions, enabling smarter budget allocation and higher ROI, rather than isolating any single touchpoint 11. For enterprise blog programs, that means two measurement tools running in parallel. Multi-touch attribution assigns fractional credit across the sessions and content interactions that preceded a conversion, capturing the assist patterns that last-click erases. Marketing mix modeling operates at a higher altitude, evaluating channel-level effectiveness against sales data and external factors like seasonality and macroeconomic trends 12.
MMM is particularly relevant to SEO blogs because it is privacy-safe and does not depend on individual session tracking, which continues to degrade as third-party signals disappear. The tradeoff is that MMM is a model, not a fixed formula, and its outputs move with the assumptions built into it 12. The operational discipline is to document those assumptions alongside the outputs so that when a quarterly review challenges the blog's contribution number, the team can explain how it was produced rather than defend a black box.
Budgeting the Blog as Long-Cycle Demand Creation
The blog belongs on the brand-building side of the marketing ledger, not the performance side, and the budgeting conversation gets clearer the moment that classification is made explicit. Google's analysis of effective spend mix cites a 50% to 60% brand-building allocation and a 40% to 50% performance allocation as the range associated with stronger long-term ROI 13. SEO blogs functionally operate as brand-building assets because they compound over quarters and years, shape category perception, and produce demand that surfaces later through channels other than the blog itself.
Classifying the blog this way changes what the CFO expects from it. Brand-building assets are evaluated on trajectory, share of category conversation, and downstream pipeline influence measured through MMM. They are not evaluated on the cost per conversion of a single asset in the current quarter. That expectation reset is often the highest-leverage conversation a VP of Marketing can have during planning, because it moves the blog out of the performance column where it will always look expensive against paid channels and into the column where its actual mechanics are visible.
The budget itself follows the reclassification. Long-cycle demand creation gets funded on a rolling annual basis with quarterly checkpoints, not a monthly cost-per-lead threshold that penalizes assets before they have had time to rank, accumulate links, and enter the consideration paths they were built to serve.
Surviving Core Update Volatility with Governance-Based Reporting
Core updates are the moment measurement discipline pays off. Google's May 2026 core update ran from May 21 through June 2, and any blog with meaningful search dependency saw quarterly traffic patterns break inside that twelve-day window 3. Teams reporting on sessions and rankings enter these windows with nothing to say except that traffic moved. Teams reporting on governance have a different conversation available.
Governance-based reporting shifts the primary metric from output volatility to input quality. What did the team publish this quarter, against which decision-stage clusters, with which named authors, and against what originality standard. Which assets passed structured data validation before shipping. Which recommendations were approved and which were declined, and why. Those inputs are stable across core updates because they measure what the team controlled, not what Google's ranking systems decided in a given week.
The output metrics still get reported, but as trailing indicators rather than headline numbers. A traffic dip that coincides with a core update becomes a diagnostic question about which clusters moved and why, not a performance failure. The measurement stack, in other words, absorbs volatility instead of transmitting it directly to the CFO's dashboard.
Operating the Three Layers Together: A 90-Day Sequence
Three layers do not install in parallel. They install in sequence, because measurement without architecture reports on the wrong assets, and workflow without measurement optimizes for output that no one has proven pays back. A 90-day sequence gets the layers stood up in the order that lets each one earn its keep.
- Days 1 through 30 belong to architecture. Map every active cluster to a named buying decision, cut the assets that cannot name a source of originality, and set the schema types each cluster will carry. The deliverable is a decision-anchored cluster map with per-asset originality gates, not a keyword spreadsheet. Google's helpful content guidance provides the editorial standard the map has to clear 1.
- Days 31 through 60 install the workflow. Stand up the signal-to-approval loop, name the editor accountable for sign-off, and record AI-assistance provenance from the first asset forward, aligned to NIST AI RMF governance principles 4. Consolidate FTC disclosure defaults into the workflow before any content crosses into paid distribution 5.
- Days 61 through 90 turn on measurement. Wire multi-touch attribution against the decision-stage tags built in month one, and commission the first MMM read as a baseline for the annual budget conversation 11, 12. By day 90, the blog reports as an operating system, not a calendar.
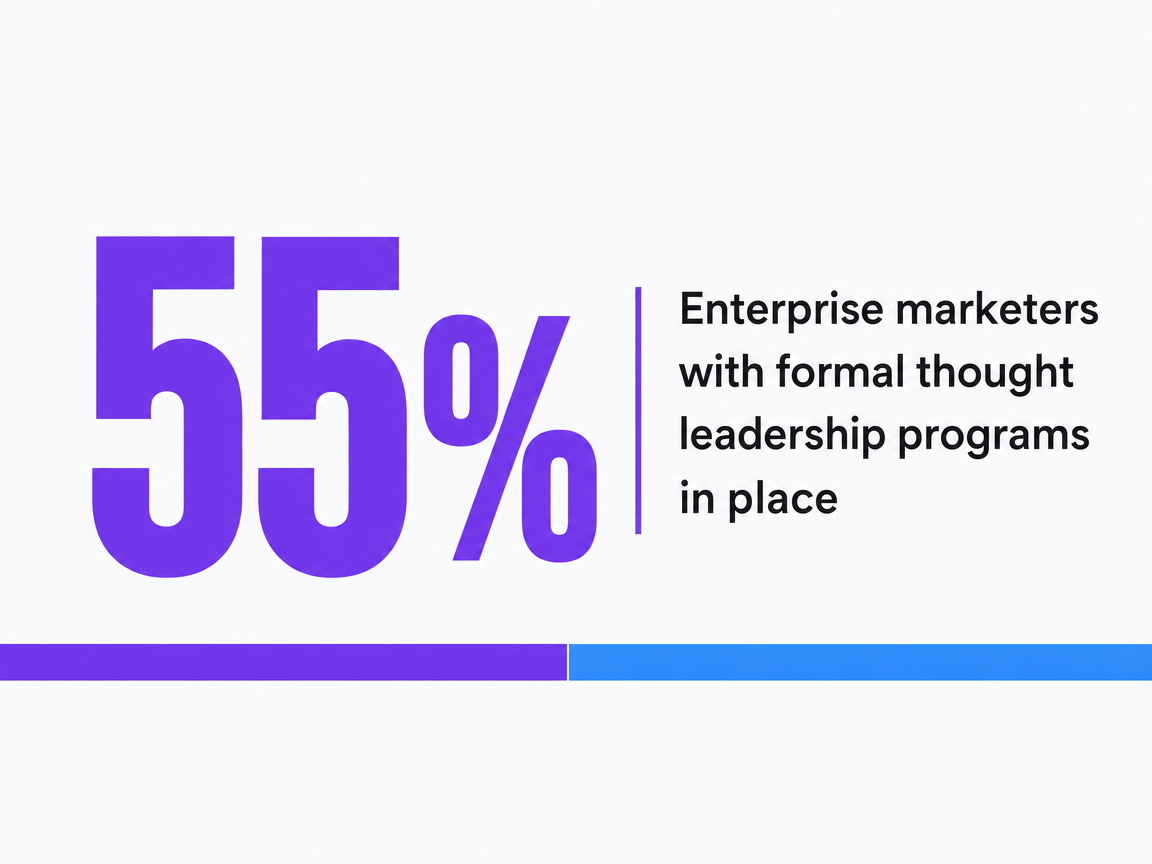 Enterprise marketers with formal thought leadership programs in place
Enterprise marketers with formal thought leadership programs in place
Enterprise marketers with formal thought leadership programs in place
Frequently Asked Questions
References
- 1.Creating helpful, reliable, people-first content.
- 2.Rich Results Test.
- 3.May 2026 core update - Google Search Status Dashboard.
- 4.AI Risk Management Framework.
- 5.Native Advertising: A Guide for Businesses.
- 6.Disclosures 101 for Social Media Influencers.
- 7.B2B Content and Marketing Trends: Insights for 2026.
- 8.Enterprise Content and Marketing Trends: Insights for 2026.
- 9.Enterprise Content and Marketing Trends for 2026.
- 10.Content Marketing Measurement in 2026: The Audience Trust Index.
- 11.ROI and AI-powered measurement strategies - Think with Google.
- 12.Marketing mix modeling to measure ROI - Think with Google APAC.
- 13.Unlock the hidden 50% of your marketing ROI in 2025.
- 14.Marketing 2025: Drive profitable growth.