
Key Takeaways
- LocalBusiness markup functions as the entity layer feeding the Local Pack, Knowledge Panel, and AI answer cards from a single JSON-LD block, not a per-page rich result hint.
- Sub-type precision, sameAs links, identifiers, structured geo and hours, and hasOfferCatalog carry more disambiguation weight than basic NAP fields when answer engines bind pages to entity nodes.
- Portfolio governance—template inheritance, a single source-of-truth record per location, and monthly GBP parity validation—prevents the drift that erodes entity confidence across multi-location accounts.
- Measure schema work through entity recognition completeness, surface coverage, and GBP-to-schema parity rates rather than fabricated ranking-lift percentages, and omit aggregateRating when the review corpus cannot be reconciled under FTC guidance.
Schema as the entity layer Google and AI systems read first
When multiple businesses share similar names or locations, search systems rely on a disambiguation step to match them to the correct real-world entity. This process heavily depends on the structured attributes a web page exposes. Research on knowledge graph entity disambiguation highlights the goal: matching ambiguous entities to corresponding entities in the knowledge graph using structured features that differentiate one node from another 2. LocalBusiness markup provides the highest-fidelity version of these features that a publisher controls.
This redefines the role of markup on a location page. It's not merely a styling hint for rich results; it's the upstream source feeding three downstream surfaces from a single JSON-LD block: the Local Pack, the Knowledge Panel, and the AI answer card. Each surface reads the same entity definition, but only if the @type, sameAs, address, geo, and identifier values provide sufficient signal for the system to bind the page to a specific node rather than guess among candidates. Agencies that treat schema as a per-page checkbox often introduce inconsistencies across a portfolio. Those who view it as the foundational entity layer achieve the consistency that disambiguation algorithms reward.
Why LocalBusiness markup now governs AI answer eligibility
Generative AI systems do not infer entity identity from prose on a location page. Instead, they retrieve information from indexed entity records. These records are most reliably populated by structured data that explicitly declares @type, address, geo, and sameAs relationships within a parseable block. A Pew analysis of web browsing data indicates that a significant portion of web sessions now involve interactions with AI-mediated content, positioning AI as a routine layer in information discovery 8. This shift elevates local business schema from a Local Pack optimization tactic to a prerequisite for being cited in AI answer surfaces that synthesize information from multiple local candidates.
The underlying mechanics relate to how knowledge graphs are constructed. Stanford's overview describes knowledge graphs as data structures central to representing information extracted from diverse sources and feeding machine learning models 3. AI answer engines leverage these representations. When an AI surface generates a response about a business, it draws from entity records compiled from structured signals: the markup on the location page, the verified Google Business Profile, citation data, and other machine-readable inputs. A page lacking LocalBusiness schema doesn't disappear, but it forfeits the most precise input for its entity record, leaving its description to be reconstructed from prose, third-party directories, and aggregators.
For agency SEO leads, the implication is clear: AI answer eligibility is now a portfolio-wide schema challenge, not a page-specific enhancement. A client portfolio with inconsistent or missing JSON-LD across numerous location pages risks misclassification, incorrect merging with other entities, or being overlooked by answer generators that find more reliable data elsewhere. While the Local Pack still prioritizes proximity and prominence, the AI answer layer above it favors entities with unambiguous, complete, and consistent machine-readable definitions across the web.
The property set that actually moves the needle
Identity and disambiguation: @type, name, sameAs, identifier
The @type declaration is the primary signal an answer engine processes. It not only labels the page but also binds the entity to a specific class within the Schema.org hierarchy, which downstream systems map to candidate nodes in their knowledge graphs. For example, a LegalService declaration conveys different information than Attorney, and both differ from a generic LocalBusiness. The more precise the type matches the actual service category, the fewer candidate nodes the disambiguation process needs to evaluate against the page.
The 'name' property is straightforward only when it precisely matches the legal entity name on the Google Business Profile, state registration, and across citations. Variations, such as "Smith Dental" versus "Smith Family Dental, PC," create discrepancies that disambiguation methods aim to resolve using structured features 2. The sameAs property is frequently underutilized. Linking to the verified Google Business Profile URL, Wikidata node (if available), LinkedIn company page, and authoritative directory profiles provides explicit pointers to the same entity across the web. Identifier values, such as DUNS, NPI for healthcare, and state bar numbers for legal professionals, add a crucial layer of binding that proximity signals cannot replicate.
Place and reach: address, geo, areaServed, openingHoursSpecification
The PostalAddress should be structured, with streetAddress, addressLocality, addressRegion, postalCode, and addressCountry as distinct fields, rather than a single string. The geo property, containing latitude and longitude as a GeoCoordinates object, allows the system to precisely bind the entity to a physical point. This is particularly important in dense urban areas where multiple addresses might be in close proximity.
The areaServed property is often overlooked but critical. A single dental office might serve several adjacent municipalities. Without areaServed declared as an array of City or AdministrativeArea objects, the page provides no machine-readable evidence of this broader reach. For service-area businesses without a physical storefront, areaServed combined with serviceArea is the primary geographic information available to the system.
openingHoursSpecification should use the structured form, not the legacy openingHours string. Each OpeningHoursSpecification object includes dayOfWeek, opens, and closes, and can support validFrom and validThrough for seasonal schedules, holidays, and temporary closures. This structured format enables the Local Pack and AI surfaces to accurately answer "is it open now" queries and helps prevent inconsistencies when Google Business Profile hours change but the page is not updated.
Service and offer: hasOfferCatalog, makesOffer, knowsAbout
The hasOfferCatalog property is where many location pages revert to unstructured prose, losing the benefits of entity classification. An OfferCatalog containing itemListElement entries, each modeled as an Offer wrapping a Service with a defined name, description, and serviceType, provides the system with an explicit list of the entity's offerings. For example, a dental group offering implants, orthodontics, and pediatric care can produce three distinct Service nodes that the answer layer can match against query intent, rather than relying on a single page mentioning all three in body copy.
makesOffer covers similar ground at the entity level when a full catalog structure is unnecessary, suitable for service-area businesses with a limited number of primary services. knowsAbout extends the entity definition to include topical authority, declaring subjects in which the business possesses expertise without necessarily offering them as productized services. For a law firm, knowsAbout values covering specific statutes, procedural areas, or case types signal topical relevance that aligns well with the structured features favored by disambiguation algorithms 2.
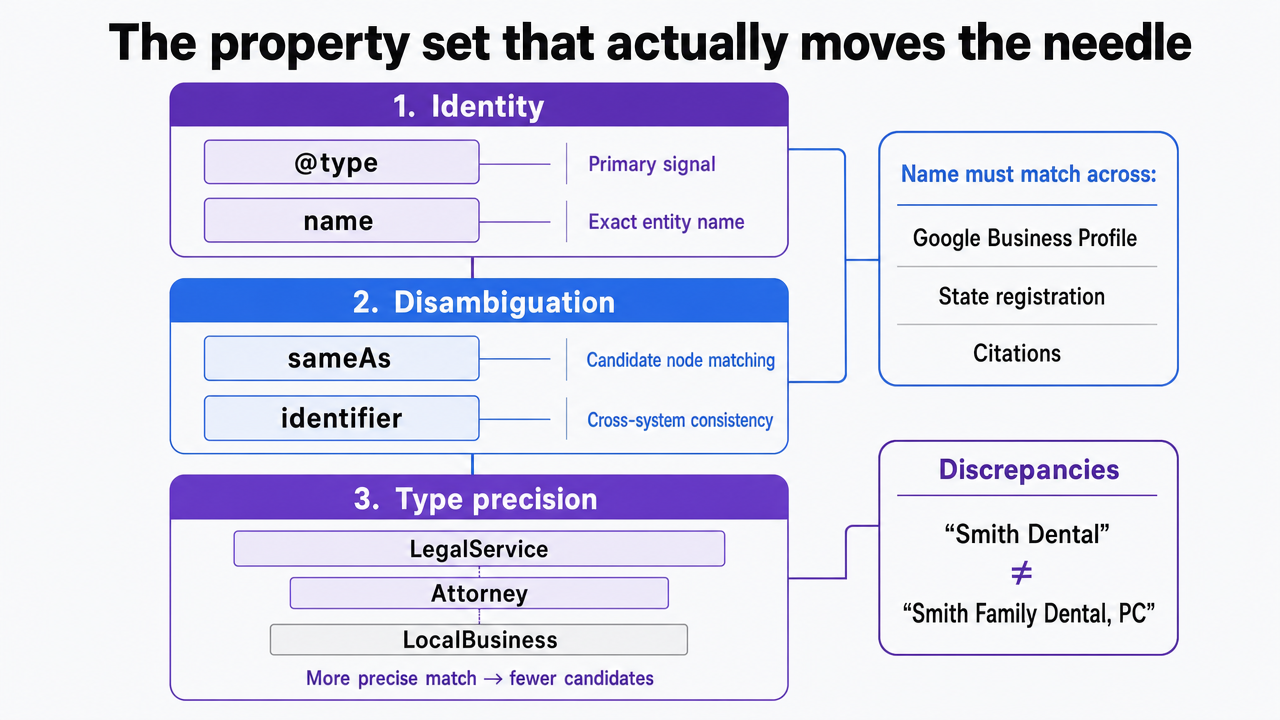 Visualize the three property groupings explained in this section as a structured reference framework
Visualize the three property groupings explained in this section as a structured reference framework
Test local business schema impact risk-free
See real-time effects of structured data on local pack rankings before making any long-term commitment.
Picking the right sub-type for AI entity classification
Sub-type selection is a critical decision in location page templating. Declaring @type as LocalBusiness when a more specific class exists signals to the system that the publisher hasn't precisely defined the entity's function. This ambiguity propagates downstream, affecting how the AI answer layer binds the page to relevant nodes. Knowledge graphs, as described by Stanford, are fundamental data structures for representing information and feeding machine learning models 3. The classes within Schema.org directly map into these representations, making the sub-type choice the page's initial classification vote.
The vertical-to-sub-type mapping is often more specific than agencies assume. A general dental practice should declare @type as Dentist, not the broader MedicalBusiness or generic LocalBusiness. The more specific class carries inherited service expectations that the answer layer can match against intent queries like "pediatric dentist near me." However, an oral surgery group within a multi-specialty dental organization might be better classified under MedicalBusiness with a specialty property, as its procedural scope extends beyond typical dental boundaries. Law firms align well with LegalService, while Attorney is more appropriate for individual practitioner pages. Home services fall under the HomeAndConstructionBusiness branch, with specific terminal classes like Plumber, Electrician, RoofingContractor, and HVACBusiness to be used when applicable. Financial advisors, accountants, and insurance agencies fit under FinancialService, with AccountingService and InsuranceAgency as terminal nodes.
For agency SEO leads managing diverse client portfolios, the operational rule is to select the deepest class in the Schema.org tree that accurately describes every page using the template. Additional service details should then be declared through hasOfferCatalog and knowsAbout, rather than diluting the primary type. Only revert to LocalBusiness when no more specific terminal class fits, which is less common than many CMS defaults suggest.
Entity consistency across GBP, schema, citations, and on-page content
Disambiguation algorithms are enhanced by the consistent repetition of identical structured features across all surfaces where an entity appears 2. If a Google Business Profile lists "Westside Family Dental," the JSON-LD declares "Westside Family Dental PLLC," a Yelp citation says "Westside Dental," and the page footer reads "Westside Family Dentistry," the system encounters multiple candidate strings. It then has to determine which references bind to the same entity. Each unresolved variant slightly reduces entity confidence, a problem that compounds across a portfolio.
Seven key data points are crucial for consistency:
- legal name
- street address (including unit designator)
- primary phone number in a canonical format
- primary category
- latitude and longitude coordinates
- structured hours of operation
- the canonical website URL (including protocol and trailing-slash convention)
Each of these appears in at least four locations read by the system: LocalBusiness JSON-LD, the GBP listing, top-tier citations, and on-page rendered content. Inconsistencies in any of these create similar disambiguation challenges, albeit on a smaller scale.
The operational discipline required is a single source-of-truth record for each location, stored independently of the CMS, GBP management tool, and citation manager. Schema generation, GBP updates, and on-page rendering should all draw from this central record. When a location's hours change, updating this single source ensures that all downstream surfaces inherit the change simultaneously. Without such an upstream record, agencies often manually reconcile multiple systems for every change, which is a primary cause of portfolio drift.
Review and rating markup under current FTC enforcement
aggregateRating and review markup represent a high-liability area within the LocalBusiness property set, and understanding the regulatory landscape is crucial before deploying it across a portfolio. The FTC's 2023 revised Endorsement Guides formally established expectations that customer reviews used in marketing must be truthful, non-deceptive, and disclose any material connection between the endorser and the business 6. This standard extends to structured data: a star rating displayed in the Local Pack or an AI answer card is a marketing claim, not neutral data, and the publisher is responsible for the overall impression it creates 7.
Three implementation rules directly stem from this guidance.
- aggregateRating values must reflect the actual, unfiltered review population collected by the business, not a curated subset that omits negative entries. Selectively displaying only positive reviews while calculating an aggregateRating from the full set, or vice versa, creates the misleading net impression specifically targeted by the FTC Endorsement Guides 5.
- reviewCount must correspond to a verifiable source, typically the same review corpus visible on the site or a connected first-party review widget. Inflated counts from unattributed third-party sources create substantiation problems, which small-business advertising guidance identifies as a reasonable-basis failure 7.
- Individual Review objects embedded in markup must include author, datePublished, and reviewBody values that accurately match the published review. Any incentivized review must clearly disclose the incentive within the reviewBody itself, adhering to the clear-and-conspicuous disclosure standard 5.
For regulated industries, the implications are even greater. Legal and healthcare entities must comply with state bar and professional licensing rules in addition to FTC standards. Legal analysis of the revised Guides emphasizes that misleading testimonial claims remain deceptive regardless of the technical channel used 11. The operational rule for agency SEO leads: review and rating markup should only be implemented when the underlying review collection process, the displayed corpus, and the structured values are fully reconciled. If not, it is safer to omit aggregateRating from the schema entirely to avoid risking a deceptive net impression across Local Pack, knowledge panels, and AI answer surfaces simultaneously.
See How Structured Local Business Schema Drives Measurable Local Pack Results
Connect with our team to review data-backed schema strategies proven to increase local SERP prominence and support AI-powered visibility for multi-location brands.
Portfolio governance: templating, validation, and approval workflows
Template inheritance and variable injection across location pages
Manually coding LocalBusiness JSON-LD for each location is a primary cause of portfolio drift. A large dental group with different developers working on each of its 60 locations can result in 60 subtly different markup blocks, each potentially having missing properties, inconsistent geo formats, or outdated hours. Downstream disambiguation systems don't see a single entity expressed 60 times; they see 60 candidate strings competing for binding to the same node 2.
The governance pattern effective at scale is template inheritance with strict variable injection. A single parent template defines the LocalBusiness schema structure, property set, formatting conventions for phone numbers and URLs, and fixed brand-wide values (e.g., corporate sameAs URLs, brand-level identifiers, default areaServed). Child templates inherit this structure and inject only location-specific variables, which are read from the source-of-truth record. These include street address, geo coordinates, hours, location-specific service catalog entries, and the location's GBP URL. No location page should render schema from unstructured prose or one-off developer input. Every field should trace back to either the parent template or the location record, and the rendering pipeline should fail if a required variable is missing, preventing partial markup.
JSON-LD validation pipelines and GBP parity checks
Schema that validates in the Rich Results Test on deployment day may not remain valid across a portfolio for six months. Hours change, services are added, addresses are updated, phone systems migrate, and any of these can break parity between the rendered JSON-LD and the Google Business Profile listing. A scheduled validation pipeline, rather than just a launch-day check, is essential for catching such drift.
This pipeline should include three key checks.
- Structural validation: ensuring every location page's JSON-LD parses cleanly, validates against Schema.org type definitions, and contains all required properties declared by the brand template.
- GBP parity: a programmatic comparison of the seven core data points (name, address, phone, primary category, geo coordinates, hours, website URL) between the JSON-LD on the page and the GBP API response for the same location. Mismatches should be surfaced as actionable differences, not silent failures.
- Cross-portfolio consistency: brand-level fields that should be uniform across all locations (e.g., corporate sameAs URLs, parent organization references, brand identifier values) are checked for uniformity, preventing a single rogue template update from propagating 60 inconsistent records into the entity layer.
Per-location production economics for multi-location agencies
This section addresses agency SEO leads managing schema delivery for multi-location portfolios, such as DSOs and franchise accounts, where schema work is priced per location. The economic question isn't whether to implement LocalBusiness markup, but which production model maintains profitability as the number of locations scales from 10 to 200.
Three delivery models are common, each with different per-location time costs, drift rates, and governance overhead. The table below uses variables for implementing teams to fill in based on their own rate cards and portfolio sizes. McKinsey's 2024 survey on enterprise AI adoption found that organizations reporting measurable benefits from generative AI were concentrated in functions with templated, high-volume work, including marketing operations 1, which aligns with the structure of multi-location schema production.
| Delivery model | Hours per location (initial) | Hours per location (annual maintenance) | Drift risk | Approval governance |
|---|---|---|---|---|
| In-house specialist hand-coding | H₁ × N locations | M₁ × N locations | High (per-page variation) | Manual review per page |
| Agency retainer with developer handoffs | H₂ × N locations + brief cycles | M₂ × N locations + ticket queue | Medium (handoff loss) | Per-ticket sign-off |
| AI-assisted templated production with human approval | Parent template build + V × N variable injection | Validation pipeline runtime + diff review | Low (template-bound) | Single approval per template change; diff approval per drift event |
The choice of model depends on portfolio size (N), the agency's loaded hourly rate, and the rate of change in underlying location data. Vectoron's $599/mo trial operates within the third model, emphasizing approval-first execution where template changes and drift remediation require human sign-off before any markup is deployed.
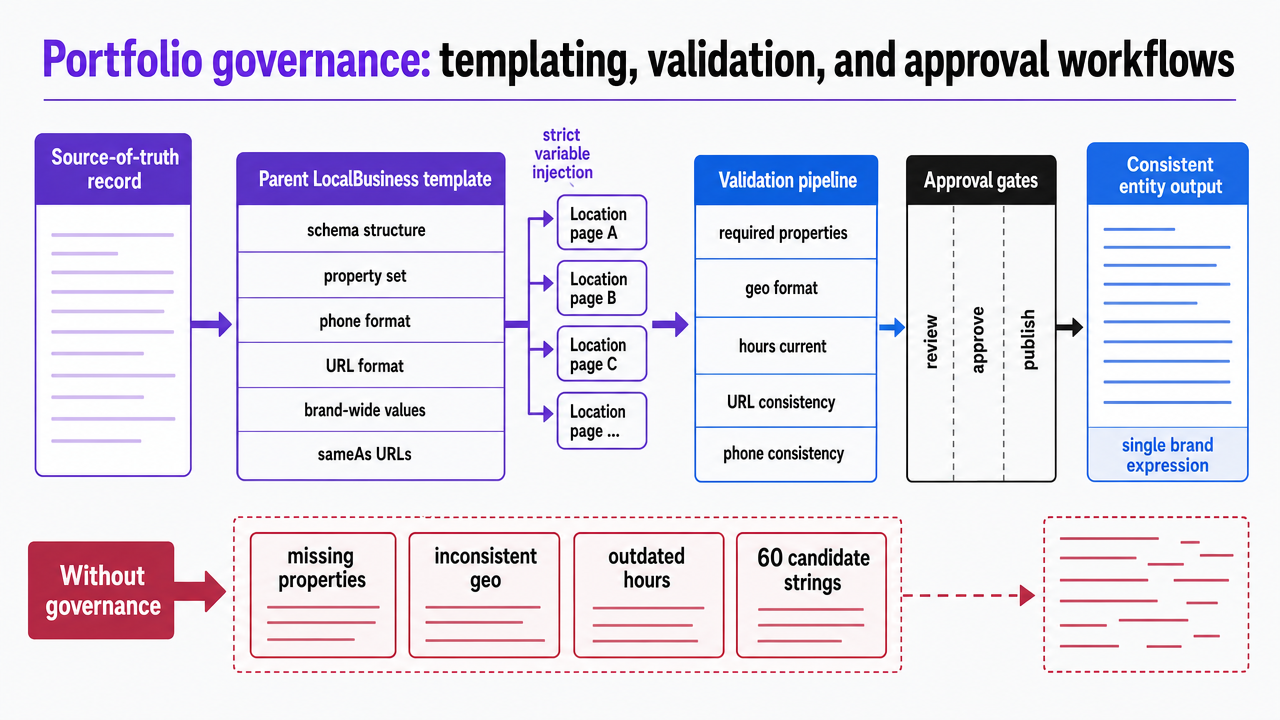 Visualize the governance pipeline described in this section—source-of-truth record flowing through template inheritance into validation pipeline with approval gates
Visualize the governance pipeline described in this section—source-of-truth record flowing through template inheritance into validation pipeline with approval gates
Measuring schema impact without inventing metrics
Schema impact does not manifest as a straightforward ranking-lift percentage, and any agency claiming such attribution is fabricating the data. An honest measurement framework identifies three observable signals that LocalBusiness markup genuinely influences, treating each as a leading indicator rather than a direct conversion metric.
The first is entity recognition completeness. Search Console's enhancement reports, the URL Inspection API, and third-party crawl tools can verify whether each location page renders valid LocalBusiness markup with the declared property set intact across the portfolio. This metric is binary per location and aggregable: the percentage of locations with complete, valid, and GBP-parity schema in the current month. Drift events then become a measure of governance health, not ranking attribution.
The second is surface coverage. Knowledge panel presence, Local Pack inclusion for branded and category queries, and citations in AI answer surfaces can each be tracked as a per-location yes/no across a defined query set. The change in coverage over time, correlated with the schema deployment timeline, provides the most defensible link between markup and visibility. Pew's browsing analysis confirms that AI surfaces are now a routine part of information discovery, justifying tracking AI citations as a distinct surface rather than merging them with organic results 8.
The third is the GBP-to-schema parity rate, reported monthly. Parity is an operational metric clients can act upon; promising ranking lifts is a practice agencies should discontinue.
What changes next as AI surfaces become the default local interface
The trajectory is evident in browsing data. Pew's analysis shows that AI-mediated content is no longer a niche interaction but a regular feature of how users navigate the web 8. For local discovery, this means the focus is shifting from "which page ranks in the Local Pack" to "which entity gets cited when an answer engine compiles a recommendation." These involve different selection mechanisms and reward different inputs.
Three operational shifts for portfolio-scale schema work are emerging.
- The property set will continue to expand beyond the core NAP (Name, Address, Phone) into relationship properties like parentOrganization, brand, department, and member. This is because AI answer engines reasoning about large multi-location organizations need to understand which nodes belong to the same parent entity.
- Validation cadence will become more frequent. Quarterly schema audits will be insufficient given the speed at which AI surfaces re-index and re-cite information. Monthly parity checks, automated difference reporting, and template-bound rendering will become the standard.
- The approval surface will broaden. Every schema change now propagates to Local Pack, Knowledge Panel, and AI answer outputs simultaneously, increasing the cost of any single erroneous deployment.
Agency SEO leads who establish this governance layer now—implementing template inheritance, source-of-truth records, parity pipelines, and approval-first execution—will build entity authority across evolving AI surfaces. Those who continue to treat LocalBusiness markup as a per-page deliverable will spend the next cycle addressing inconsistencies while AI answer layers cite competitors.
Frequently Asked Questions
References
- 1.The state of AI in early 2024.
- 2.A Knowledge Graph Entity Disambiguation Method Based on ....
- 3.An Introduction to Knowledge Graphs.
- 4.Americans' Changing Relationship With Local News.
- 5.FTC's Endorsement Guides: What People Are Asking.
- 6.Guides Concerning the Use of Endorsements and Testimonials in Advertising.
- 7.Advertising FAQs: A Guide for Small Business.
- 8.What Web Browsing Data Tells Us About How AI Appears Online.
- 9.Key findings about how Americans view artificial intelligence.
- 10.What Web Browsing Data Tells Us About How AI Appears Online.
- 11.The FTC Publishes Revised Guides concerning the Use of Endorsements and Testimonials in Advertising.