
Key Takeaways
- SEO now runs as a production system with unit costs and approval gates, so the VP's real job is designing the pipeline rather than directing individual assets through it.
- Cost per published, ranking-eligible asset is the metric that survives CFO scrutiny, because it ties organic investment to a compounding yield curve paid channels cannot match.
- The operating model choice — agency, in-house, or productized AI-augmented workflow — sets the monthly output ceiling, with AI owning volume work and humans owning positioning, editorial, and publish decisions.
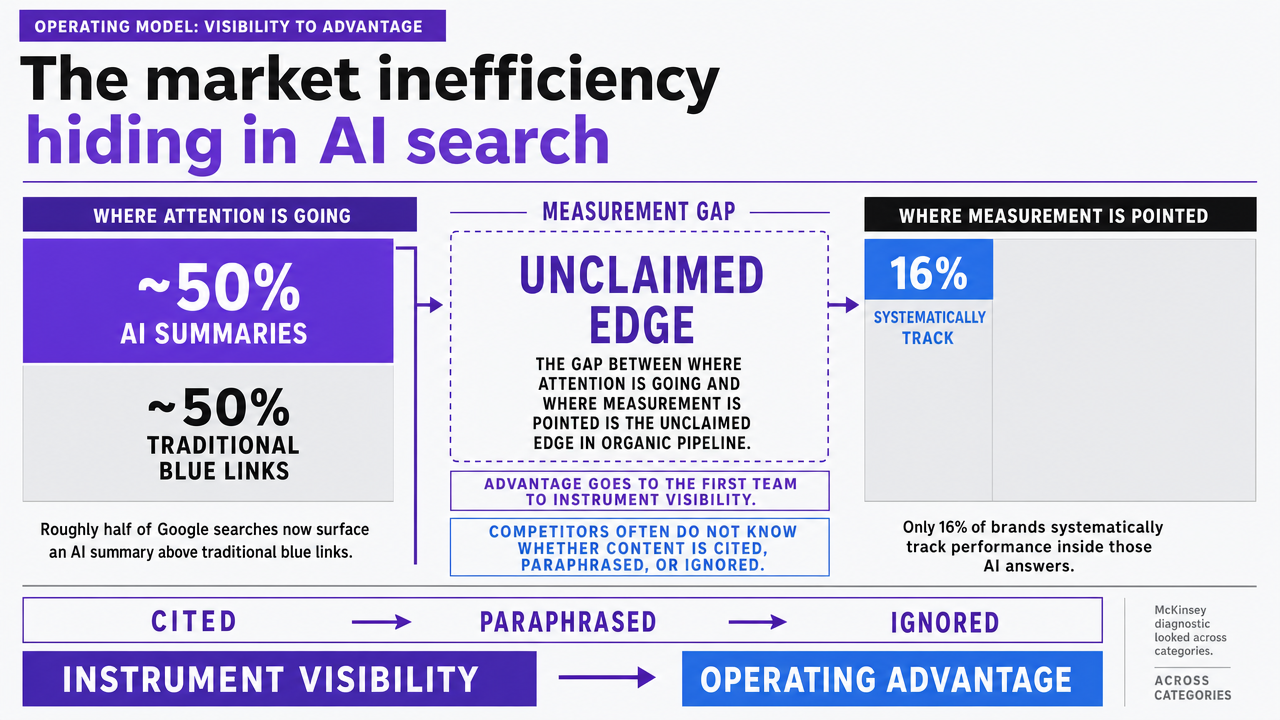
- AI summaries appear on roughly half of Google searches but only 16 percent of brands track performance inside them 3, making AI-summary visibility the near-term measurement edge to instrument first.
The SEO function is now an operating model, not a channel
Marketing leaders who still treat SEO as a channel line item are managing a category that no longer exists. The function has quietly reclassified itself. It is now a production system with defined inputs, quality gates, and unit costs — closer to how an operations leader would describe a manufacturing line than how a CMO would describe a media buy.
The economics forced the shift. A recent McKinsey analysis of generative AI's impact on the enterprise estimates that the marketing function could capture productivity gains worth 5 to 15 percent of total marketing spend, largely by automating research, drafting, and analytical work that used to consume analyst hours 16. This is a mandate to redesign how the work gets produced, not just which tools get purchased.
Scaling growth and marketing is no longer about adding headcount, but about systems, standardization, and leverage that let a smaller team produce more of what actually compounds 15. Applied to SEO, this means the VP's real job is designing the pipeline — who researches, who drafts, who approves, who publishes, who measures — rather than personally directing every asset through it.
Three consequences follow. First, the unit of analysis is no longer the keyword or the campaign; it is the published, ranking-eligible asset and its cost to produce. Second, the operating model choice — agency, in-house expansion, or productized AI-augmented workflow — determines the ceiling on monthly output more than any tactical decision inside those models. Third, human judgment concentrates at fewer, higher-leverage points: positioning, editorial approval, and prioritization. The rest of this piece works through each of those consequences in order.
The market inefficiency hiding in AI search
Roughly half of Google searches now surface an AI summary above the traditional blue links, yet only 16 percent of brands systematically track how they perform inside those AI answers, according to McKinsey's analysis of the AI search shift 3. The gap between where attention is going and where measurement is pointed is the largest unclaimed edge in organic pipeline right now.
For a VP running a lean team, the implication is unusually direct. When the majority of competitors do not know whether their content is being cited, paraphrased, or ignored by AI-generated answers, the first team to instrument that visibility gets an operating advantage that does not depend on outspending anyone. It depends on measuring what most peers still treat as invisible.
McKinsey's diagnostic looked at brand behavior across categories, not just B2B tech or service verticals, so the 16 percent figure is a market-wide baseline rather than a niche anomaly. It also predates the wave of AI Overview expansion, which suggests the tracking gap is widening faster than most measurement stacks are adapting.
Two operational moves follow from this. The first is diagnostic: audit which queries in the existing keyword set already return an AI summary, whose content is being surfaced inside those summaries, and where the brand appears or fails to appear. That audit rarely requires new headcount — it requires assigning the question to someone and giving them a repeatable process. The second is structural: adjust the content brief so that assets are written to be quotable by an AI answer, not just rankable in a ten-blue-link SERP. That means clearer entity definitions, tighter first-paragraph claims, and structured data that machines can parse without ambiguity.
The competitive moat here is temporary by design. McKinsey's own guidance frames generative engine optimization as a capability brands should be building now, not a permanent arbitrage 3. The window is open because most marketing functions are still arguing about whether AI search matters. The VPs who treat it as a measurement problem this quarter — not a strategy debate next year — get to define category presence before the tracking becomes standard practice and the advantage compresses.
 Reinforce the central statistic that only 16% of brands systematically track AI search performance, framing the measurement gap as the market inefficiency the section describes
Reinforce the central statistic that only 16% of brands systematically track AI search performance, framing the measurement gap as the market inefficiency the section describes
Content unit economics: the number the CFO will actually ask about
Every SEO budget conversation with a CFO eventually collapses into a single question: what does it cost to produce one asset that can actually rank and convert, and how many of those can the team ship per month? The marketing vocabulary around SEO — impressions, sessions, domain authority — does not answer that question. Unit economics does. Once the VP can name a cost per published, ranking-eligible asset and defend it against a paid-media alternative, the SEO investment stops being a faith-based line item and starts being a manufacturing budget with a known return curve.
Defining cost per published, ranking-eligible asset
The metric has three parts, and each one filters out work that looks productive but never compounds.
- "Published" excludes drafts stuck in review purgatory.
- "Ranking-eligible" excludes assets that never had the search demand, structural quality, or internal linking to compete for a position — the ones that get written because someone had an opinion, not because a query justified it.
- "Asset" is the unit: one page, one guide, one comparison, one location landing page.
The cost side is equally strict. It includes research and briefing hours, drafting cost (whether human, AI-augmented, or hybrid), editorial review, SEO QA, publishing labor, and the portion of tooling and platform spend attributable to that asset. It excludes reporting overhead and executive time, which belong in program cost, not unit cost.
Once that number exists, three things become visible that were invisible before:
- The output ceiling — how many assets the current operating model can produce per month without quality collapse.
- The break-even payback — how many months of organic sessions the average asset needs to recover its production cost.
- The marginal cost curve — whether the tenth asset in a month costs the same as the second, or whether the team is running past its capacity into diminishing returns.
Why organic compounds where paid does not
The CFO's follow-up question is predictable: why not just spend the equivalent budget on paid acquisition and skip the production complexity? The answer is in the yield curve, and it is where organic earns its multi-quarter defense.
Analysis of B2B tech organic marketing tactics finds that organic channels generate roughly three times more leads than paid advertising at comparable investment levels, driven by compounding visibility and lower dependence on ongoing media spend . That multiple is not a promise every asset delivers on day one — it is the ceiling that a properly instrumented organic program approaches as its content library ages and accumulates rankings.
The mechanical difference matters more than the headline number. A paid campaign's cost per lead is roughly constant across its life; when spend stops, leads stop within the same billing cycle. A ranking asset's cost is front-loaded — most of the expense sits in the production month — and its lead contribution accrues across the following quarters as it accumulates positions, backlinks, and internal link equity. The unit cost stays fixed while the return numerator keeps growing. That is what compounding looks like on a P&L.
Two implications shape the CFO conversation. First, organic and paid should not be evaluated on the same time horizon. A twelve-month view flatters paid; a twenty-four-month view flatters organic. The honest comparison uses cost per lead in year one against cost per lead across the full amortization window. Second, the compounding effect only exists if the asset was ranking-eligible in the first place. A library of published-but-unrankable pages produces the same yield curve as paid: it stops working when the spend stops, because the assets never earned independent visibility.
That is why the unit definition in the previous section matters to the finance conversation. Cost per ranking-eligible asset is the number that ties SEO investment to the compounding curve the CFO is being asked to believe in.
Three operating models a VP can actually choose
Once the unit cost is defined, the operating model choice becomes the biggest lever a VP controls. Three models dominate the market, and each one puts a different ceiling on monthly output for the same budget.
The traditional agency retainer buys senior strategy and a delivery team the VP does not have to manage, at the cost of briefing cycles, revision rounds, and a monthly output that rarely flexes without a new statement of work. In-house expansion trades that friction for direct control, but pushes fixed cost into the base and makes the output ceiling a function of hiring speed. The productized AI-augmented workflow moves research, drafting, technical audits, and monitoring into a repeatable system that runs against an approval queue, keeping fixed cost low and treating monthly volume as a throughput setting rather than a headcount decision .
The question is not which model is universally right. It is which model matches the VP's pipeline target, cost per ranking-eligible asset, and tolerance for approval overhead.
Comparing agency retainer, in-house expansion, and productized AI-augmented workflow
The comparison below uses five variables a VP already tracks: cost per published asset, time-to-publish, monthly output ceiling, human approval touchpoints, and the location of the actual production work. Dollar figures are omitted deliberately — supplied research does not include reliable retainer or salary benchmarks, and inventing them would corrupt the comparison. The point is the shape of each model, not a false precision.
| Variable | Agency retainer | In-house expansion | Productized AI-augmented workflow |
|---|---|---|---|
| Cost per published asset | Fixed to retainer scope; marginal assets billed separately | Loaded with salary, benefits, and management overhead per FTE | Variable cost dominated by tooling and review labor |
| Time-to-publish | Gated by briefing, revision, and delivery cycles | Gated by team capacity and competing priorities | Gated by approval queue depth, not production speed |
| Monthly output ceiling | Fixed by retainer tier; scales via renegotiation | Scales with hires; lags demand by one to two quarters | Scales with approval capacity and tooling throughput |
| Human approval touchpoints | Brief in, draft out; feedback rounds vary | Continuous, embedded in team workflow | Concentrated at positioning, editorial, and publish gates |
| Where the work happens | Vendor team, off the VP's system of record | In-house team, inside the VP's system | AI executes research, drafts, and audits; humans approve and direct |
Two structural differences drive the choice. The first is where variable cost lives. Agency and in-house models push most cost into fixed commitments — a retainer or a salary line — which caps flexibility when pipeline demand shifts mid-quarter. A productized workflow keeps the cost variable enough that monthly output can move up or down without renegotiation or reorganization .
The second is where human attention gets spent. In an agency model, senior time goes to briefing and revision management. In an in-house expansion, it goes to hiring, onboarding, and people management. In a productized AI-augmented model, the VP's team spends its hours on the three decisions that actually compound: what to publish, whether the draft is good enough to ship, and where the next asset should be aimed. Research, drafting, and technical monitoring move to AI systems that operate against a defined approval queue .
McKinsey's estimate that generative AI could deliver marketing productivity gains worth 5 to 15 percent of total marketing spend is the sourced anchor for what the productized model can defend to finance . That range assumes the AI work is instrumented and reviewed — not that a tool is bought and left to run. The peer-reviewed SME evidence is more direct on this point: productivity gains from AI tools are conditional on implementation quality, not automatic, and poorly integrated deployments can add friction rather than remove it .
The operational takeaway is narrower than the model debate suggests. The VP does not have to choose one model forever. The choice is which model owns the next twelve months of output, and which parts of the existing stack get retired or reassigned to make that model actually run.
Where AI executes and where humans still own the call
The productized model only defends itself if the split between machine work and human work is drawn deliberately. A vague split — "AI helps with content, humans review it" — collapses back into either a shadow agency workflow or an in-house team drowning in draft revisions. The useful frame is narrower: identify the specific SEO tasks where AI produces reliable output at speed, and identify the decisions where a human's judgment is the actual product being sold to the search engine and to the buyer.
The task inventory below draws directly from the operational categories where AI-augmented SEO has been documented to produce compounding gains — keyword research, real-time optimization, technical audits, and predictive analytics — with the caveat that the peer-reviewed evidence on SME marketing productivity is explicit that these gains depend on implementation discipline, not on tool selection . The governance layer that follows describes how a lean team actually enforces that discipline without turning approval into a bottleneck.
The AI-augmented task inventory
Four categories of SEO work move cleanly to AI systems once the workflow is defined.
- Keyword research and semantic clustering — parsing search demand into topic groups, mapping queries to funnel stages, and flagging cannibalization risk — is now a first-draft task for AI, with a human editor selecting which clusters actually match the brand's positioning .
- Technical audits fall into the same category: crawling for broken internal links, schema gaps, indexation errors, and Core Web Vitals regressions is repeatable, rule-based work that AI handles faster than a human analyst and without fatigue drift .
- Draft generation and on-page optimization: outlining, first-pass copy, meta description variants, entity coverage, and internal link suggestions.
- Monitoring — rank tracking, SERP feature changes, competitor content shifts, and AI-summary appearance flags — where AI's advantage is running the check hourly instead of monthly.
Across all four, the pattern holds: AI produces the artifact, a human accepts, rejects, or redirects it.
The approval-first governance layer
Approval-first governance means nothing ships to the site, the index, or the buyer without a named human signing off. In a lean team, that gate concentrates at three places:
- The brief — does this asset match positioning and search demand.
- The draft — is the argument, evidence, and voice defensible.
- The publish decision — does the technical implementation match the brief.
Everything upstream of those three gates can be AI-executed; everything at the gates is human.
The reason the gate has to be explicit is that AI adoption among content marketers has climbed from 65 percent to 95 percent in the two-year window measured by Orbit Media's survey of practicing content marketers, which means the competitive advantage no longer comes from using AI — it comes from governing it better than peers who deployed the same tools without the same review discipline . The SME productivity research reinforces the point directly: productivity gains materialize when AI outputs pass through structured human review, and reverse into friction when they do not .
The operational rule is simple. AI owns the volume side of the equation. Humans own the taste side. When the two get confused — humans doing keyword research by hand, AI approving its own drafts — the model breaks in both directions.
Signal-based prioritization for a lean SEO team
A lean SEO team runs out of hours before it runs out of ideas. The question is not what to work on next — the backlog is always full — but which item in the queue actually moves pipeline in the next ninety days. Signal-based prioritization is how outbound teams have been answering that question, and the logic transfers directly to inbound SEO once the input signals get named.
The B2B outbound playbook that formalized signal-based prioritization argues that maxed-out teams close their execution gap not by adding capacity, but by ranking work against intent and opportunity signals before anyone touches a task . For an SEO team, the equivalent signals are already in the stack:
- Pages ranking in positions four through fifteen (one editorial pass from the first page).
- Queries where an AI summary now appears but the brand is absent.
- Assets with declining click-through despite stable rank.
- Clusters where a competitor shipped three new pieces in the last quarter.
Each signal maps to a different action:
- Position-four-to-fifteen pages get refresh briefs, not new drafts.
- AI-summary gaps get restructured intros and schema updates.
- CTR decliners get title and meta rewrites.
- Competitor velocity clusters get calendar priority.
The team stops debating which project matters and starts working a ranked queue.
The operational discipline that makes this work is the same one that separates repeatable pipeline from busy work: standardize the input, standardize the response, and let the ranking do the arguing . Judgment concentrates on the top of the queue, not on the queue itself.
If the VP oversees multiple locations or brand portfolios
The operating model discussion changes shape when a single VP owns SEO across a portfolio — a multi-location service business, a franchise network, a group of practices, or a parent brand with several sub-brands. The unit of work stops being the asset and becomes the location-and-asset pair. Cost per ranking-eligible asset now multiplies by the number of locations that need a version of it, and the approval queue that worked for one brand voice fractures across regional managers, franchisees, and compliance reviewers who all want a say before publish.
The failure mode is predictable. Portfolio VPs either centralize hard — one brief, one draft, one publish, with location names swapped in — and lose the local relevance that makes location pages rank. Or they decentralize — each location writes its own — and lose consistency, quality control, and any semblance of unit economics. Both routes cap output well below what the pipeline target requires.
The productized AI-augmented model resolves the split by separating the parts that must be identical from the parts that must be local. Positioning, service definitions, schema patterns, and technical standards are templated once and applied programmatically across locations. Local proof — reviews, staff names, service-area language, market-specific query variations — gets generated per location against a shared brief and routed to the location owner for approval before publish . Central marketing stops writing every page. It owns the template, the quality bar, and the approval structure that lets one lean team ship location coverage that would otherwise require a regional content hire per market.
Defending the investment: the metrics that survive a budget review
Budget reviews kill SEO programs that report on sessions, keyword counts, and domain authority. Those metrics do not tie to pipeline, and finance has learned to discount them. The metrics that survive a review are the ones that connect production activity to revenue movement, and they fit on a single page.
Four numbers do the work:
- Cost per published, ranking-eligible asset — the unit cost defined earlier — anchors the program to a manufacturing budget the CFO can benchmark.
- Sourced organic pipeline, measured as opportunities and closed revenue attributed to organic entry, ties output to the number the VP owns.
- Payback period per asset — months of organic sessions and pipeline needed to recover production cost — tells finance when compounding actually starts.
- Share of ranking-eligible queries where an AI summary now appears, with brand presence tracked inside those summaries, closes the measurement gap that most competitors have not yet noticed .
The productivity uplift band from generative AI is the frame that ties these numbers to the operating model choice. McKinsey's cross-functional analysis estimates that generative AI can capture value equivalent to 5 to 15 percent of total marketing spend, contingent on how the work is instrumented rather than which tools are purchased . That range is defensible in a budget review because it comes from a named analysis with a defined scope, not from a vendor forecast. It also sets a realistic expectation: the productized workflow does not promise a doubling of output; it promises a measurable, sourced band of productivity that finance can model against the current cost base.
The reporting cadence matters as much as the metric set.
- Monthly review covers cost per asset and approval throughput.
- Quarterly review covers payback progression and AI-summary share.
- Annual review covers the operating model itself — whether the ceiling on monthly output still matches the pipeline target, or whether the model that worked last year is now the constraint.
Platforms like Vectoron were built around exactly this reporting shape: an approval-first workflow where the metrics that defend the investment are the same ones the team uses to run it.
Frequently Asked Questions
References
- 1.Exploring the potential of AI to increase productivity in small and medium-sized enterprises.
- 2.The Benefits of Organic SEO: Why It Still Matters.
- 3.Winning in the age of AI search.
- 4.The Most Effective AI Uses for Content Marketing in 2025 [New Research].
- 5.AI Marketing Statistics: How Marketers Use AI in 2025.
- 6.Proven Organic Marketing Tactics for B2B Tech Success in 2026.
- 7.What is Organic Search and How Does It Affect Your Business?.
- 8.What Is Organic Search? Why It Matters for Growth.
- 9.Organic SEO Services: Costs, Benefits & What's Included.
- 10.How AI Is Transforming Digital Marketing in 2024 and Beyond..
- 11.Scaling Sales Isn't About Headcount, It's About Repeatable Pipeline.
- 12.How to Scale B2B Pipeline Without Adding Headcount - A Signal-Based Outbound Playbook.
- 13.Scaling Revenue Without Adding Headcount.
- 14.AI & SEO: A Symbiotic Partnership for Search Dominance in 2024.
- 15.Scaling growth and marketing is no longer about adding headcount..
- 16.The economic potential of generative AI: The next productivity frontier.