
Key Takeaways
- The agency-versus-AI decision now turns on operating model rather than output quality, with regulatory anchors like the NIST AI RMF 3and FTC Operation AI Comply 7pushing procurement closer to legal and finance.
- Evaluate vendors on four levers—strategy ownership, substantiation, throughput, and accountability—because each determines whether the function head directs the program or merely reviews deliverables produced under undocumented authority.
- Allocate workstreams instead of picking a side: humans keep strategy and link relationships, AI runs briefs, technical audits, and reporting, and drafting splits by claim density with mandatory review on substantiated pages.
- Use procurement questions mapped to NIST's govern, map, measure, and manage functions 3, 4to surface whether a vendor can produce per-URL provenance artifacts and an incident response protocol on demand.
- Multi-location operators face linearly scaling per-location retainers against flat account-level AI production costs, so consolidation pays once duplicate strategy work and parallel approval queues are priced into the comparison.
- A defensible 2025 hybrid concentrates humans on judgment-heavy decisions and AI on consistency-heavy production, backed by per-URL substantiation records and FTC-ready evidence for any performance claim before it ships 5.
The decision has moved from quality to operating model
Most SEO buyer guides still frame the agency-versus-AI question as a quality contest. That framing is out of date. The output gap between a competent agency team and a governed AI production stack has narrowed to the point where deliverables look interchangeable on the page. What separates them now is the operating model underneath: who owns strategy, who can substantiate claims, who absorbs production volatility, and who is on the hook when something fails audit.
Two regulatory anchors make this shift unavoidable for any Head of Growth signing a 2025 contract. The NIST AI Risk Management Framework defines governance, mapping, measurement, and management as the baseline practices buyers should expect from any vendor producing content with AI in the loop 3. The FTC's 2024 Operation AI Comply sweep made clear that performance claims attached to AI-powered services are subject to the same truth-in-advertising standards as any other marketing claim, and that enforcement is active, not theoretical 7.
The practical consequence: a procurement decision that used to live with the content lead now sits closer to legal, finance, and the function head. The right comparison is no longer "which deliverable looks better." It is which operating model produces ranked, substantiated, auditable output at a unit cost the program can defend twelve months from now. The rest of this article works through that comparison on four levers and a workstream allocation, then closes with consolidation economics for operators running more than one site.
Four levers that actually separate agency and AI delivery
Strategy ownership: who decides what gets ranked and why
Strategy ownership is the lever buyers misread most often. An agency retainer typically includes a strategist title on the SOW, but the actual decisions about topic clusters, target query sets, and the internal link graph are often executed by a junior account team working from a templated playbook. The function head ends up reviewing deliverables rather than directing the program.
AI-led production inverts that pattern when it is set up correctly. The Head of Growth retains strategy ownership because the system surfaces competitor gap data, cluster maps, and query priorities as recommendations the operator approves or rejects. The NIST AI RMF treats this distinction as foundational: the “govern” function specifies that human oversight, role clarity, and decision authority must be defined before any AI workflow produces output that goes to market 3.
The practical test is simple. Ask the prospective vendor — agency or AI — who signs off on the cluster map, who owns the query-to-URL assignment, and where that decision is documented. If the answer is buried in an account manager’s inbox or a black-box recommendation engine with no approval surface, strategy ownership has effectively been outsourced. That is acceptable for some programs and unacceptable for any program where the function head is measured on pipeline contribution.
Substantiation: who stands behind the claims in published copy
Every published page makes claims. Some are explicit performance claims; many more are implicit claims about clinical outcomes, product capability, pricing, or comparative advantage. The FTC substantiation standard is the same regardless of who drafted the copy: claims must be truthful, not deceptive, and supported by evidence in hand at the time of publication 5, 6. The 2024 Operation AI Comply sweep extended that standard explicitly to AI-powered services and AI-generated marketing output, with enforcement actions against companies that overstated what their systems could deliver 7.
That regulatory posture changes the substantiation question for buyers. With a traditional agency, substantiation usually lives in a shared Google Doc that the client is expected to review before publish — an arrangement that works until volume scales past the function head’s review capacity. With AI-led production, substantiation has to be engineered into the workflow: source attachment per claim, citation logging, and a reviewable artifact for each page that goes live.
The buyer’s diligence question is concrete. For any claim on any published URL, can the vendor produce, within an hour, the source the claim was drafted against and the reviewer who approved it? If the answer is no, the program is carrying substantiation risk that does not show up in a deliverables report but will show up the first time a competitor, regulator, or plaintiff’s attorney asks. Agencies and AI vendors both fail this test routinely. The buyer’s job is to test it before signing.
Throughput: who absorbs production volatility
Throughput is where the economics diverge sharply. An agency’s production capacity is bounded by its current roster: writers, editors, SEO specialists, and project managers under contract this quarter. When the program needs forty briefs in three weeks instead of the planned twenty, the agency either declines, subcontracts to freelancers it does not directly manage, or pushes the timeline. The volatility lands on the client.
AI-led production reallocates that volatility to the platform. McKinsey’s State of AI 2025 survey, which measured how organizations deploy AI across functions including marketing, found a median of 17% of respondents reported workforce declines in some functions tied directly to AI adoption, and that “Top Performers” were roughly twice as likely as other respondents to capture measurable value from their AI and cloud investments 12. The number is not a forecast for any specific SEO program; it is a directional read on what happens when content and analysis workloads move into governed AI workflows at scale.
For a Head of Growth, the operational consequence is that throughput stops being a negotiation. A program that needs to ship 12 briefs one week and 48 the next runs at the same unit cost either way, and the variability that used to drive scope-change emails moves inside the production system. The constraint shifts from labor capacity to approval bandwidth — which is a constraint the function head actually controls.
Accountability: who answers when rankings, claims, or audits fail
Accountability is the lever that decides what happens after something goes wrong — a deindexed page, an unsubstantiated claim flagged by legal, a Core Web Vitals regression that tanks a money template, or an audit request from a regulator. Agency contracts typically cap liability at fees paid in the prior three to six months, which is a manageable number for the agency and a meaningless one for the client whose pipeline just took the hit.
The NIST AI RMF’s “manage” function frames accountability as a documented chain: who approved the work, what evidence supported the approval, and what response protocol activates when a measured outcome diverges from the predicted one 3. The Generative AI Profile sharpens that requirement for AI-produced content specifically, calling out provenance, traceability, and incident response as buyer-side expectations 4.
The practical accountability test for any SEO vendor is whether the program can answer three questions on demand. Who approved this page? What was the substantiation at time of publish? What changed when the page’s ranking, traffic, or claim status moved? An agency that cannot answer those questions inside an hour is selling deliverables, not accountability. An AI vendor whose platform cannot generate those answers from log data is selling output, not a governed production system. The distinction matters most on the day the function head has to brief the CEO on what just happened.
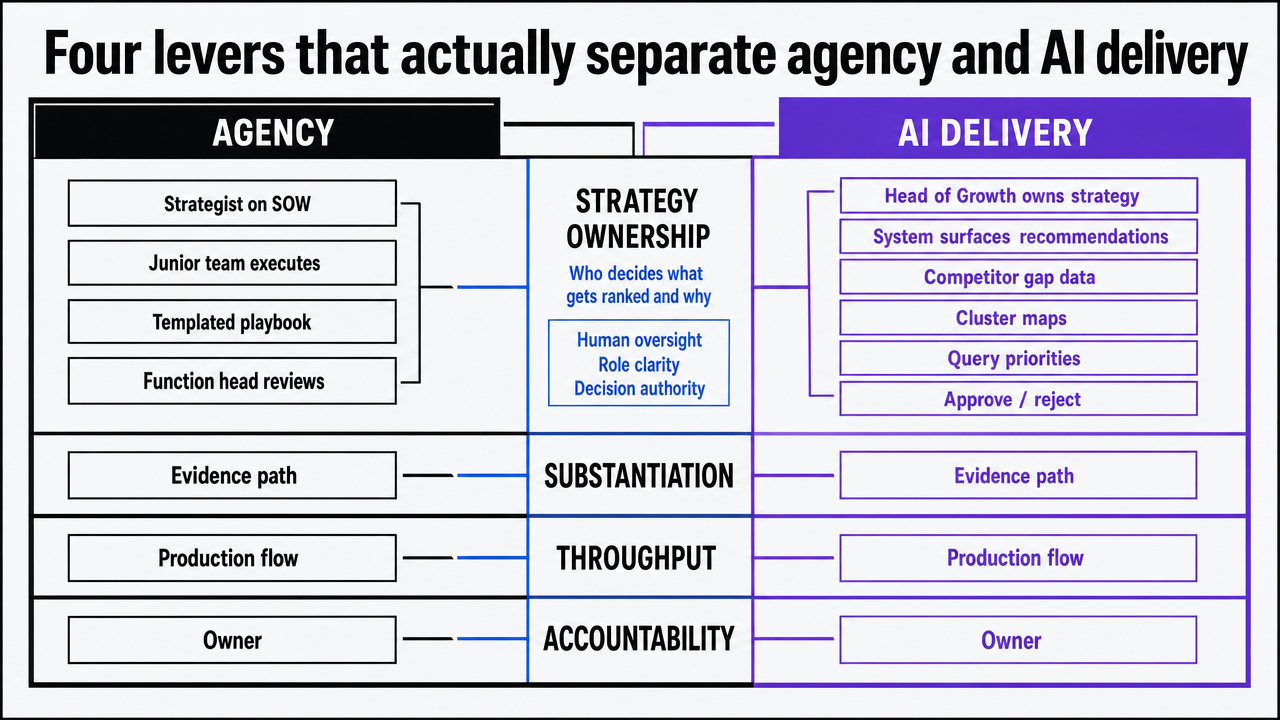 Visualize the four comparison levers (strategy ownership, substantiation, throughput, accountability) as a side-by-side framework between Agency and AI delivery models, directly mirroring the section's structure
Visualize the four comparison levers (strategy ownership, substantiation, throughput, accountability) as a side-by-side framework between Agency and AI delivery models, directly mirroring the section's structure
Test AI-powered SEO execution on real campaigns
Experience end-to-end SEO workflow and publish live content before making any commitment.
A workstream-by-workstream allocation, not a binary choice
The mature programs running in 2025 do not pick a side. They allocate. The useful question is not whether agency or AI produces better SEO output in the abstract, but which side of the production line each workstream sits on once governance and unit cost are both priced in. Six workstreams cover the bulk of what an SEO program actually ships: strategy, briefs, drafting, technical audits, link acquisition, and reporting. Each has a different risk profile against the NIST AI RMF's govern, map, measure, and manage functions 3.
Strategy is the workstream that should stay closest to the function head regardless of vendor. Cluster definition, query prioritization, and the decision about which URLs carry pipeline weight are governance decisions, not production tasks. AI can supply the gap analysis and the candidate cluster maps; a human owns the approval. Briefs are the inverse case. They are pattern-heavy, evidence-driven, and reviewable against a checklist, which is exactly the workload where AI production runs at lower cost and higher consistency than a rotating bench of freelance strategists. The map function — documenting context, scope, and intended use — carries the substantiation weight, and that documentation is easier to enforce in a system than in an inbox.
Drafting splits by claim density. Top-of-funnel educational pages and comparison content with low substantiation risk move cleanly into AI production. Money pages, pages making clinical or financial claims, and pages tied to regulated assertions stay under human authorship or, more often, AI drafting with mandatory expert review at the manage stage. Technical audits are the strongest pure-AI case in the stack: log file analysis, crawl diagnostics, schema markup validation, and Core Web Vitals monitoring are continuous measurement problems that a governed system handles at a cost agencies cannot match. Link acquisition is the opposite — relationship work, outreach judgment, and risk screening on referring domains still favor human operators, with AI used for prospecting and qualification rather than execution. Reporting collapses to AI by default once measurement pipes are wired, with the function head spending time on interpretation rather than slide assembly.
The allocation that holds up under audit looks roughly like this: humans own strategy and link relationships, AI owns briefs, technical monitoring, and reporting, and drafting is split by claim risk with mandatory review on anything substantiated. That split is not a compromise. It is what the RMF's govern-map-measure-manage logic produces when applied workstream by workstream rather than at the contract level 3.
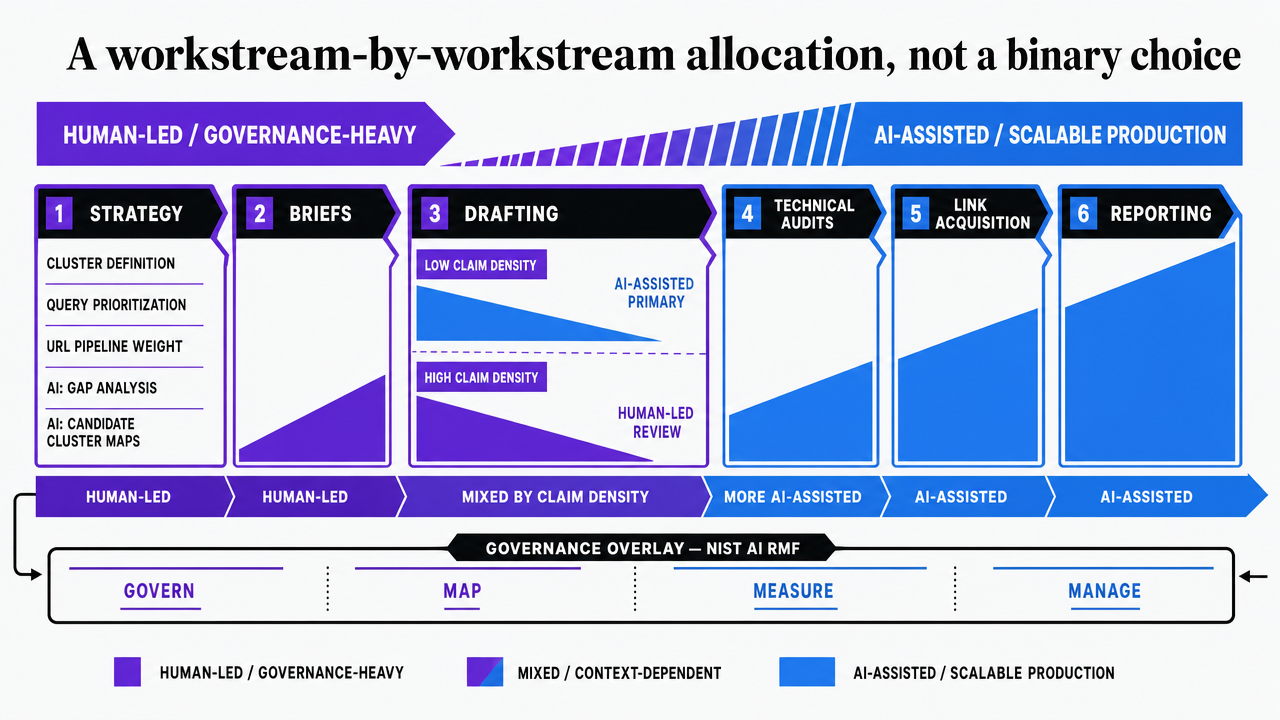 Visualize the six-workstream allocation between humans and AI described in the section, including the split-by-claim-density drafting category
Visualize the six-workstream allocation between humans and AI described in the section, including the split-by-claim-density drafting category
Procurement questions that surface real governance gaps
Most vendor scorecards still test for case studies, ranking screenshots, and team bios. None of those surface the governance gaps that decide whether a program will hold up under an FTC inquiry or an internal audit. The questions below pull from the NIST Generative AI Profile's provenance and oversight requirements 4and the FTC's substantiation standard as enforced through Operation AI Comply 7. They work for agency pitches and AI platform demos without modification.
Govern. : Who in your organization owns the AI use policy, and can the buyer see it? Which roles have decision authority over what gets published, and how is that authority documented per page? If the vendor cannot name a policy owner and produce the policy, the govern function is informal — which means it does not exist in any way that survives turnover.
Map. : For a given URL, what was the intended use, the target query, the substantiation source, and the reviewer? A vendor that cannot produce a per-page artifact covering those four fields is selling content, not a mapped production system 4.
Measure. : What is measured beyond rankings and traffic? Specifically: claim accuracy rate, citation coverage, model output drift, and editorial reject rate. A vendor that measures only output volume is not measuring risk.
Manage. : What is the incident protocol when a claim is challenged, a page is deindexed, or a regulator requests substantiation? Who responds, on what SLA, and what evidence package is produced? Agencies often improvise this. Governed AI platforms log it.
Two FTC-specific questions close the list. Can the vendor show, for any performance claim in its own marketing, the evidence in hand at the time the claim was made 5? And does the vendor warrant that AI-generated copy delivered to the client will meet the same substantiation standard before it ships 6? A vendor that hedges on either question is asking the buyer to absorb its compliance risk.
 Visualize the four NIST RMF functions (Govern, Map, Measure, Manage) as a procurement scorecard, mirroring the section's structure of buyer diligence questions
Visualize the four NIST RMF functions (Govern, Map, Measure, Manage) as a procurement scorecard, mirroring the section's structure of buyer diligence questions
See How AI-Driven SEO Outperforms Traditional Agency Models—Backed by Real-World Benchmarks
Request a detailed comparison of AI-powered SEO execution versus agency delivery, including workflow breakdowns, cost-per-output metrics, and efficiency benchmarks relevant to enterprise-scale or multi-location operations.
If you manage multiple locations: consolidation economics
Why per-location retainers stop scaling
The framework above applies to any growth team, but the math changes meaningfully for operators running more than one site or service line. Most agency retainers were priced for single-location clients and never re-engineered when the same buyer showed up with eight, twenty, or fifty footprints. The contract structure stayed per-location even when the work stopped being per-location in any operational sense.
The duplication is visible to anyone who has approved the invoices. Local schema markup, Google Business Profile optimization, and review monitoring vary by address, but the keyword research, competitor analysis, internal link graph design, and editorial briefs underneath them are substantively the same across locations in the same service line. Charging $3,000 or $5,000 per location per month for work that compounds at the program level produces line items the function head cannot defend to finance.
The second failure mode is coordination overhead. Each location typically gets its own account manager touchpoint, its own reporting cadence, and its own approval queue. The function head ends up triaging twenty parallel conversations to ship work that should have been one decision. That overhead is invisible in the SOW and dominant in the actual operating cost of the program.
An illustrative cost comparison across N locations
The variables below are deliberately abstract. Actual retainers vary by market, service line, and agency tier, and the point is the slope of the curve rather than any specific dollar figure. Let N equal the number of locations, R the monthly per-location agency retainer, and P the account-level platform fee for AI-led production covering the same workstreams.
| Locations (N) | Per-location retainer model (N × R) | Account-level AI production (P, fixed) | Coordination touchpoints |
|---|---|---|---|
| 1 | R | P | 1 account, 1 approval queue |
| 5 | 5R | P | 5 accounts, 5 approval queues |
| 20 | 20R | P | 20 accounts, 20 approval queues |
| 50 | 50R | P | 50 accounts, 50 approval queues |
The retainer column scales linearly with N because each location is priced as its own engagement. The AI production column is flat across N because the workstreams that drive cost — brief generation, technical monitoring, reporting, on-page production — run against a single account-level plan with location-specific outputs. The breakeven happens earlier than most buyers assume: in any program where R sits at typical mid-market levels and N is greater than two or three, the per-location model is paying for duplicate strategy work and parallel coordination rather than additional output.
The hidden variable is approval bandwidth. Account-level AI production removes coordination cost but concentrates approval decisions on the function head and their team. That is a feature for operators who want strategy ownership and a constraint for operators who were using the agency as a buffer against making decisions. The buyer who wants the cost compression has to absorb the approval workload that comes with it.
Regulated-vertical caveat for healthcare operators
Multi-location healthcare operators sit in the narrowest version of this decision. The consolidation economics work the same way — in fact, they work harder, because patient-acquisition marketing is a coordinated value-creation function across the system rather than a per-clinic tactic 8. A digital marketing plan for a private practice is the same plan applied to twenty practices once cluster maps, query priorities, and conversion templates are defined at the system level 9.
The caveat is governance density. Healthcare content carries claim risk that top-of-funnel SaaS content does not. The literature on AI in healthcare is consistent that acceptance remains conditional on demonstrated safety, reliability, and oversight 10, and that ethical concerns and trust barriers in AI-enabled clinical contexts extend to any AI-produced content that touches patient decisions 11. The implication for an operator considering consolidation is not to avoid AI production; it is to require that the AI production stack carries mandatory expert review on any page making clinical, outcome, or treatment claims, with the substantiation artifact attached per URL.
The defensible setup for a healthcare growth program with more than three locations: account-level AI production for cluster work, briefs, technical SEO, and reporting; human authorship or AI-with-clinician-review on every page with a substantiated claim; and a per-page provenance record that survives the next FTC inquiry or internal audit without scrambling.
A defensible hybrid split for 2025 programs
The split that survives audit and finance review in 2025 is not balanced. It is asymmetric, with humans concentrated where judgment compounds and AI concentrated where consistency compounds. The function head keeps strategy, claim approval, and link relationships. Everything else moves into governed AI production with a documented approval surface.
Operationally that looks like this. Cluster maps, query prioritization, and the URL-to-pipeline assignment stay with the Head of Growth and a small in-house team. Briefs, technical audits, schema validation, log file analysis, and reporting run inside AI production at account level, not per location. Drafting splits on claim density: educational and comparison content ships through AI with editorial review; pages carrying clinical, financial, or regulated assertions require expert sign-off before publish, with the substantiation source attached per URL 4. Link acquisition stays with humans for outreach and referring-domain risk screening, with AI handling prospecting and qualification upstream.
Two governance commitments make the split defensible rather than expedient. First, every published page carries a per-URL artifact covering intended use, target query, substantiation source, and reviewer — the map-function record the NIST Generative AI Profile expects from any AI-produced content 4. Second, performance claims in the program's own marketing meet the FTC substantiation standard before they ship, not after a challenge arrives 5. A Head of Growth who can produce both records on demand has a program that holds up. One who cannot has deliverables. Vectoron is built around that split for operators who want the cost compression without inheriting the substantiation risk.
Frequently Asked Questions
References
- 1.Artificial Intelligence Risk Management Framework - NIST.
- 2.AI Risk Management Framework | NIST.
- 3.Artificial Intelligence Risk Management Framework (AI RMF 1.0).
- 4.Artificial Intelligence Risk Management Framework: Generative AI Profile.
- 5.Advertising and Marketing | Federal Trade Commission.
- 6.Advertising and Marketing Basics | Federal Trade Commission.
- 7.FTC Announces Crackdown on Deceptive AI Claims and Schemes.
- 8.The impact of marketing strategies in healthcare systems.
- 9.Digital Marketing for Private Practice: How to Attract New Patients.
- 10.Artificial Intelligence in Health Care: Current Applications and Issues.
- 11.Trustworthy and ethical AI-enabled cardiovascular care: a rapid review.
- 12.The State of AI: Global Survey 2025.