
Key Takeaways
- Reframe the vendor search as a procurement decision, demanding written evidence of strategy, measurement, and compliance rather than accepting pitch decks and verbal assurances.
- Anchor the scorecard to four research-backed determinants—strategic clarity, audience alignment, systematic measurement, and structural specialization—because these correlate with content programs that produce results 1.
- Require positioning documents, quarterly theses tied to pipeline math, and decision histories showing what was killed, since real strategy reveals itself in what a model stops doing.
- Treat audience alignment as a structural capability proven by segmentation maps, rejection rubrics, and segment-level performance reporting, not adjectives like customer-centric on a calendar.
- Demand measurement systems with attribution chains to booked revenue, experimentation logs, and segment-level economics that a CFO can reconstruct without taking impressions on faith.
- Evaluate specialization by coordination cost: named roles, visible workflows, and a defined owner of quality control, so the VP does not silently inherit production work.
- Compare freelance rosters, AI-assisted platforms, and hybrid in-house models against identical evidence requirements, recognizing each fails the four determinants in structurally different ways.
- Run compliance as a qualifying gate before scoring, disqualifying any model that cannot document PHI segregation, native ad disclosure, and endorsement substantiation in writing 8, 9, 10.
The procurement problem disguised as a marketing decision
A regional personal injury firm with offices in four metro markets had two months to replace its outgoing agency. The VP of Marketing inherited the search: review three retainers, sign one, brief the new team by the end of the quarter. She declined the brief. Instead, she rewrote the assignment as a procurement problem and asked the CFO for a scorecard review rather than a vendor recommendation.
That reframing matters. When an in-house marketing leader sits down to evaluate SEO and content marketing services, the question is rarely "which agency is best." It is which delivery model can produce specialized work, against defined audience needs, with measurement a CFO will accept, at a coordination cost the team can actually absorb. Those are the variables empirical research on content marketing effectiveness keeps returning to 1.
Treating the decision as procurement changes what gets requested in writing. Evidence of strategy, not strategy decks. Evidence of measurement systems, not dashboard screenshots. Evidence of compliant production, not assurances. And it opens the field beyond the traditional retainer to freelance rosters, AI-assisted platforms, and hybrid in-house structures evaluated on the same criteria.
The sections that follow build that scorecard from the four determinants the research identifies, then apply it to three non-agency delivery models and a compliance gate that regulated verticals cannot skip.
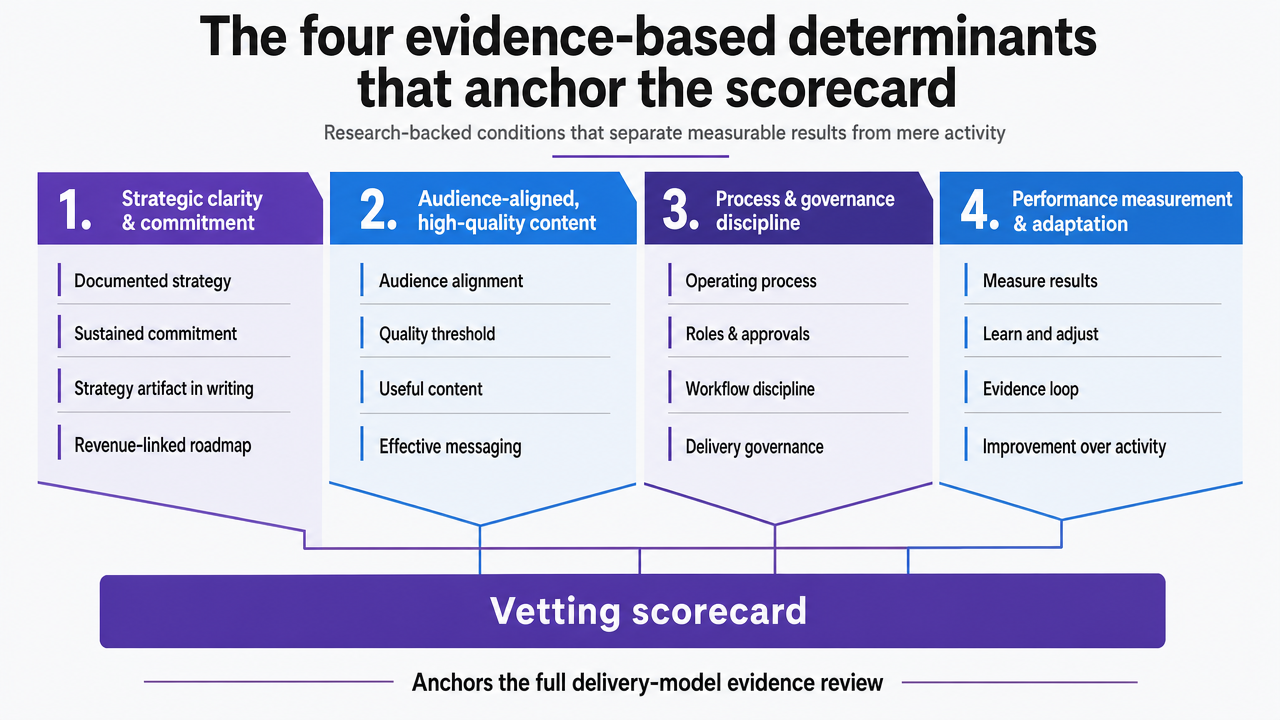
The four evidence-based determinants that anchor the scorecard
The PLOS One study of 263 senior marketers identified four conditions that separate content marketing programs that produce measurable results from those that produce activity. These are the determinants the scorecard rests on, and each one translates into a specific category of evidence a delivery model has to supply in writing 1.
Strategic clarity and commitment. : The research found that documented strategy and sustained organizational commitment correlate with higher effectiveness. For a VP, this means asking what the delivery model actually treats as the strategy artifact: a positioning document, a quarterly thesis tied to pipeline targets, a content roadmap with revenue logic attached. Verbal alignment in a kickoff call does not qualify.
Audience-aligned, high-quality content. : The same study tied effectiveness to content production governed by target-group needs and journalistic quality criteria 1. The American Marketing Association's working definition reinforces the point: content marketing is the discipline of creating valuable, relevant material that attracts and retains a defined audience, not promotional volume on a calendar 7. A delivery model needs to show how it identifies audience needs, sets quality bars, and rejects work that misses them.
Systematic performance measurement. : Effectiveness rose when teams measured content marketing performance regularly and used the data to refine the offering 1. The evidence test is whether the delivery model has an instrumented feedback loop, not a monthly PDF.
Structural specialization with enabling processes. : The study isolated structural specialization—dedicated roles, defined workflows, supporting systems—as an independent driver of effectiveness 1. Generalists wearing four hats correlate with lower outcomes. The scorecard treats specialization as a structural question, not a headcount question.
Each determinant becomes a column in the rubric. Each demands a discrete evidence artifact. The remaining sections work through what those artifacts look like in practice and how three non-agency delivery models supply—or fail to supply—them.
 Visualize the four research-backed determinants from the PLOS One framework that anchor the entire vetting scorecard, directly supporting this section's framework explanation
Visualize the four research-backed determinants from the PLOS One framework that anchor the entire vetting scorecard, directly supporting this section's framework explanation
Translating strategic clarity into vendor evidence
Strategic clarity is the determinant most likely to be faked in a pitch deck. Every vendor describes its work as strategic. The procurement task is to convert that adjective into artifacts a reviewer can hold, compare, and reject.
The PLOS One framework treats strategic clarity as documented commitment to a defined content thesis, not the existence of a strategy slide 1. For a VP running the vetting process, three artifacts separate a real strategy capability from a rehearsed one.
The first is a written positioning document specific to the operator's market and vertical, produced before any production work begins. A regional behavioral health network with three intake centers should expect a document that names the audience segments by intake pathway, identifies the search behaviors tied to each, and states which segments the program will not pursue. Vague language about thought leadership or brand awareness fails this test.
The second is a quarterly thesis tied to pipeline math. The artifact reads more like a memo than a calendar: which topics the operator will own this quarter, what organic search demand exists, what the conversion logic looks like from query to booked consultation, and what would cause the thesis to be revised mid-quarter. Editorial calendars without revenue logic attached are activity records, not strategy.
The third is a documented decision history. Strategic clarity, in operating terms, means the delivery model can show what it stopped doing and why. A vendor or platform that has never killed a topic cluster, retired an underperforming page type, or narrowed an audience definition has not exercised strategy yet. It has executed a backlog.
Audience alignment as a measurable bar, not a creative claim
Audience alignment is the determinant most often described in adjectives and least often produced as evidence. A pitch deck calls content "customer-centric." An editorial calendar lists "persona-aligned" topics. Neither passes a procurement review because neither specifies the bar the work has to clear.
The bar is set outside the agency category. McKinsey's research on personalized marketing reports that 71% of consumers expect companies to deliver personalized interactions and 76% become frustrated when that does not happen 5. The numbers describe consumer behavior across categories, not a content marketing benchmark, but the implication for a VP vetting delivery models is direct: three in four buyers arriving from organic search already expect the page, the resource, and the follow-up to recognize their context. A delivery model that cannot produce content tuned to defined audience segments at scale is operating below the threshold the audience itself has set.
The PLOS One framework treats this as a structural question, not a creative one. Effectiveness rises when production is governed by documented audience needs and journalistic quality criteria, not when writers feel close to the customer 1. The American Marketing Association's working definition reinforces the same boundary: content marketing is the discipline of producing valuable, relevant material for a defined audience, distinguished from promotional output by who it serves 7.
Three artifacts convert audience alignment from a claim into a verifiable capability.
The first is a segmentation document with search intent mapped to each segment. A 14-location dental group should expect distinct treatment of prospective implant patients researching cost, anxious parents searching pediatric availability, and adult orthodontic candidates comparing clear aligners to traditional braces. Each segment carries different queries, different objections, and different conversion logic. A single "dental patient" persona fails this test.
The second is a documented quality rubric the delivery model uses to reject its own output before it ships. The rubric names what disqualifies a draft: factual gaps, missing intent match, generic openings, absent local context. A model that cannot describe what it rejects is not exercising quality control.
The third is evidence of segment-level performance, not site-level averages. Organic sessions, assisted conversions, and booked consultations should be reportable by segment within a quarter of launch. Aggregate traffic charts hide the audiences a delivery model is failing to reach.
Test Predictable SEO Results in Real Time
Launch and measure live content campaigns before making a commitment.
Measurement systems that survive a CFO conversation
The measurement question is where most vendor evaluations quietly collapse. A delivery model that produces monthly reports is not the same as one that operates an instrumented feedback loop, and the PLOS One framework treats that distinction as decisive: effectiveness rose when teams measured performance regularly and used the data to refine the content offering itself, not when they merely reported on it 1.
A CFO will not accept impression counts as a pipeline argument. The artifact that survives that conversation traces organic sessions to qualified leads to booked revenue, by segment, with the assumptions visible. Three capabilities separate a measurement system that holds up from one that doesn't.
The first is attribution that connects search behavior to a revenue event the finance team already trusts. For a multi-location operator, that usually means call tracking by location, form submissions tagged by landing page and intent, and a closed-loop hand-off to the CRM or practice management system. A delivery model that cannot describe its attribution chain before the contract is signed will not produce it after.
The second is structured experimentation. Page templates, headline variants, internal linking patterns, and topical depth should each have a documented test history. Without it, a vendor is asserting causation it has not earned.
The third is segment-level economics. McKinsey reports that faster-growing companies derive 40% more of their revenue from personalization than their slower-growing peers, a gap that compounds when content reaches the wrong audience at scale 4. A delivery model that cannot report cost per booked consultation by segment is asking the VP to defend a number she cannot reconstruct.
Specialization at the lowest coordination cost
Specialization is the determinant most often misread as a headcount question. The PLOS One study isolated it as a structural variable: dedicated roles, defined workflows, and supporting systems correlate with higher content marketing effectiveness independent of team size or budget 1. A two-person operation with sharp role definition can outperform a ten-person mix of generalists if the workflows and systems behind them are built for the work.
The procurement question is not whether a delivery model has specialists. It is whether specialization is delivered at a coordination cost the in-house team can absorb. Every additional vendor, freelancer, or tool introduces a handoff. Each handoff carries a tax: a brief to write, a status meeting to attend, a feedback loop to chase, a quality check the VP eventually performs herself when no one else owns it.
Three signals separate productive specialization from coordination drag.
- Whether the delivery model names the specialist roles it operates—technical SEO, editorial strategy, content production, analytics—and shows how they exchange work without the VP brokering the exchange.
- Whether quality control belongs to a defined role inside the model or quietly migrates to the client.
- Whether the systems connecting the specialists are visible: a shared backlog, a single approval queue, an instrumented publishing path. Specialization without those connectors fragments into parallel monologues.
The practical test is simple. A VP should be able to draw the workflow on a whiteboard after one meeting. If she cannot, the coordination cost has already been transferred to her.
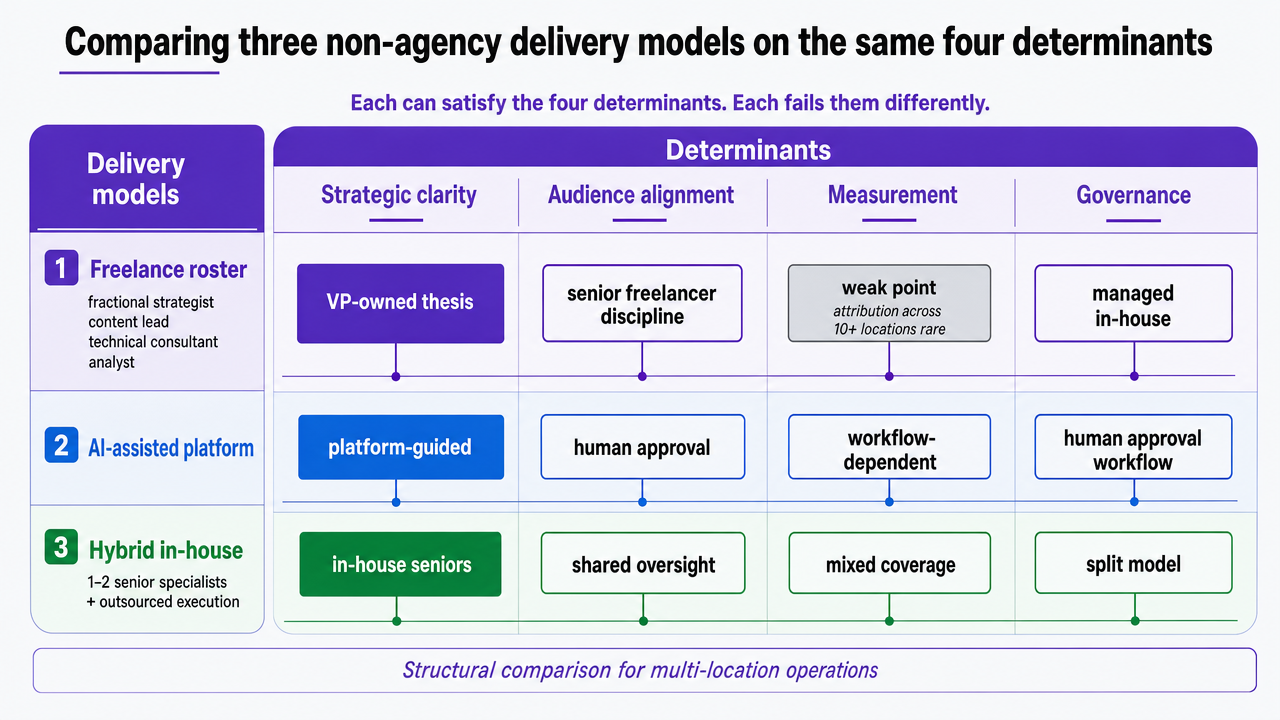
Comparing three non-agency delivery models on the same four determinants
For VPs running multi-location operations, the comparison that matters is between three non-agency delivery structures: a freelance roster assembled and managed in-house, an AI-assisted platform with human approval workflows, and a hybrid model that keeps one or two senior in-house specialists and outsources the rest. Each can satisfy the four determinants identified in the PLOS One framework. Each fails them in different ways 1.
A freelance roster typically pairs a fractional SEO strategist, a content lead, a technical SEO consultant, and an analyst. Strategic clarity is achievable when the in-house VP owns the thesis and the freelancers execute against it. Audience alignment depends on the senior freelancer's discipline. Measurement is the weak point: freelancers rarely instrument attribution across a 10-location footprint without an internal analytics owner. Specialization is real but coordination cost migrates to the VP, who becomes the de facto producer routing briefs, approvals, and QA between four contractors.
An AI-assisted platform with human approval inverts that math. Specialization is built into the system rather than assembled, and measurement is usually instrumented by default. The risk is strategic clarity: if the platform produces volume without a documented thesis the operator owns, audience alignment degrades into topic coverage. The VP's job becomes setting and revising the thesis rather than coordinating handoffs.
A hybrid model—a senior in-house content strategist plus a technical SEO contractor and a platform or freelancer for production—often scores highest on strategic clarity because the strategy lives inside the organization. It scores lower on cost efficiency at 10 locations because the in-house salary load is fixed regardless of output volume.
The economics are best evaluated as formulas the operator populates, not industry-quoted retainers. For a 10-location footprint, freelance roster cost approximates (SEO strategist hourly × hours/month) + (writer rate × pieces/month × locations) + (technical SEO retainer) + (analyst hourly × hours/month). A hybrid model adds a loaded in-house salary line. An AI-assisted platform substitutes a fixed subscription—Vectoron's post-trial price of $599/month is one published anchor in that category—plus internal approval time. The variable cells are operator-supplied; the comparison is structural, not absolute.
 Compare the three non-agency delivery models (freelance roster, AI-assisted platform, hybrid in-house) across the four determinants, directly supporting this section's structural comparison
Compare the three non-agency delivery models (freelance roster, AI-assisted platform, hybrid in-house) across the four determinants, directly supporting this section's structural comparison
See How Leading Teams Streamline SEO and Content Execution—No Agency Required
Request a walkthrough of unified, AI-driven workflows for managing SEO and content marketing services at scale, with transparent benchmarks on efficiency, pipeline impact, and approval controls for enterprise teams.
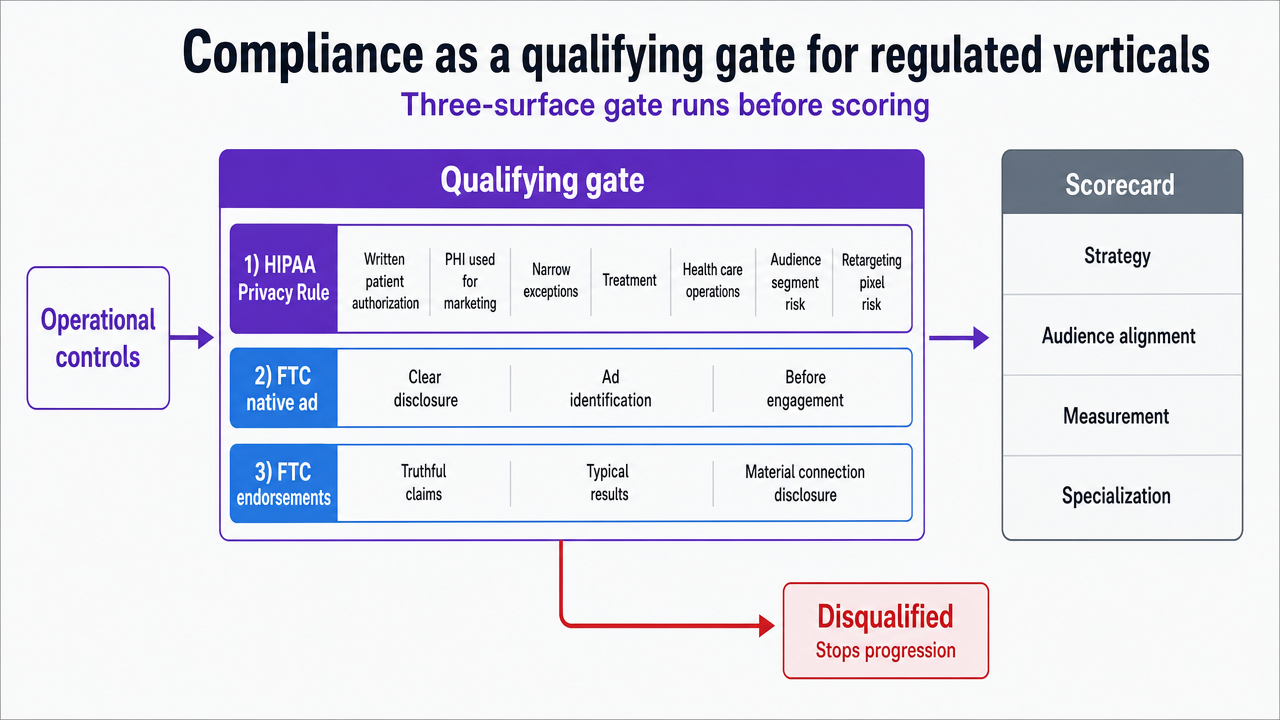
Compliance as a qualifying gate for regulated verticals
For VPs in healthcare, legal, and behavioral health, compliance is not a column in the scorecard. It is the qualifying gate that runs before the scorecard. A delivery model that cannot demonstrate operational controls against the specific rules governing the vertical is disqualified, regardless of how it performs on strategy, audience alignment, measurement, or specialization.
Three regulatory surfaces define the minimum bar. The HIPAA Privacy Rule requires written patient authorization before protected health information is used for marketing, with narrow exceptions for treatment and health care operations communications 8. The boundary between permissible outreach and impermissible marketing is operationally consequential: an intake list, a procedure-tagged audience segment, or a retargeting pixel firing on a behavioral health landing page can each cross the line if PHI is involved without authorization. A delivery model serving a behavioral health network with three intake centers has to show how it segregates PHI from its analytics and personalization stack, not assert that it does.
The FTC's native advertising guidance sets the second surface. Disclosures must be clear and conspicuous when paid content resembles editorial material, and the obligation follows the asset when it is republished in search results, social feeds, or recommendation widgets 9. SEO tactics that lean on sponsored placements, advertorials, or syndicated content carry disclosure responsibilities the in-house team inherits.
The third surface is endorsements. The FTC's endorsement guides make both the advertiser and its intermediaries—including platforms and contractors—responsible for disclosing material connections and substantiating claims in testimonials, reviews, and influencer content 10. A regional personal injury firm publishing client testimonials in optimized landing pages owns the disclosure obligation whether a freelancer, a platform, or an in-house writer produced the page.
The vetting consequence is procedural. Before any delivery model advances to the scorecard, it has to supply written answers to three questions:
- how PHI is prevented from entering content production and analytics workflows,
- how native and sponsored content is disclosed across republication channels,
- and how endorsement substantiation is documented and retained.
Verbal assurances and standard MSA language do not satisfy this gate. A model that cannot produce the controls in writing is removed from the comparison, not scored lower within it.
 Visualize the three-surface compliance gate (HIPAA, FTC native ad, FTC endorsements) that runs before scoring, supporting this section's procedural framework
Visualize the three-surface compliance gate (HIPAA, FTC native ad, FTC endorsements) that runs before scoring, supporting this section's procedural framework
Sustaining brand positioning through algorithm volatility
The scorecard so far evaluates a delivery model at a point in time. The harder test is whether it holds positioning through the volatility that defines organic search. Peer-reviewed work on SEO and brand positioning describes the underlying condition directly: marketers face an ongoing evolution of online brand positioning strategy driven by changes in search engine algorithms, and tactical responses that ignore brand objectives tend to erode the equity they were meant to protect 3.
The vetting consequence is twofold. First, a delivery model has to show how it separates positioning from ranking. A vendor or platform that treats every algorithm update as a reason to rewrite the operator's voice, narrow its topical claims, or chase whatever page format currently ranks is optimizing for a metric the operator does not own. The artifact to request is a documented record of how the model has responded to at least two major algorithm shifts: what changed in production, what stayed constant, and why.
Second, the model has to demonstrate that technical and editorial decisions ladder back to a positioning thesis the operator can defend in front of its own executive team. Keyword targeting, content depth, and link acquisition all carry brand consequences. A delivery model that cannot articulate those consequences in writing is asking the VP to absorb the reputational risk of every tactical choice it makes.
Running the scorecard: weights, evidence requirements, and disqualifiers
The scorecard runs in three passes.
- The compliance gate covered earlier: a delivery model that cannot produce written controls for PHI segregation, native ad disclosure, and endorsement substantiation is removed from the field, not scored lower within it.
- Determinant scoring.
- A weighted comparison the VP can defend in a CFO review.
The four determinants from the PLOS One framework carry the weight of the rubric 1. A defensible starting allocation for a multi-location service operator gives 30% to strategic clarity, 25% to audience alignment, 25% to measurement, and 20% to specialization at coordination cost. Operators with thinner internal analytics benches should shift five points from specialization to measurement. Operators with strong in-house strategy should do the reverse.
Each determinant requires a named artifact, not a narrative. Strategic clarity scores against the positioning document, the quarterly thesis, and the decision history. Audience alignment scores against the segmentation map, the quality rubric, and segment-level reporting. Measurement scores against the attribution chain, the experimentation log, and segment-level economics. Specialization scores against role definitions, the workflow diagram, and the location of quality control. A delivery model that cannot supply the artifact scores zero for that line. Verbal answers and recycled case studies do not count.
Two disqualifiers sit outside the scoring math. A model that cannot show how it sustained positioning through prior algorithm shifts is removed regardless of total score 3. So is a model that transfers quality control to the VP by default. Both conditions guarantee the program will fail in quarter two, whatever the rubric says in quarter one.
Frequently Asked Questions
References
- 1.Determinants of content marketing effectiveness: Conceptual framework and empirical findings from a managerial perspective.
- 2.Self-assessment checklist for federal websites (April 2024).
- 3.Search engine optimisation (SEO) strategy as determinants to online brand positioning.
- 4.The value of getting personalization right—or wrong—is multiplying.
- 5.The next frontier of personalized marketing.
- 6.Teens, Social Media and Technology 2024.
- 7.What is Content Marketing? A Beginners Guide.
- 8.Marketing (HIPAA Privacy Rule Guidance).
- 9.Native Advertising: A Guide for Businesses.
- 10.FTC's Endorsement Guides: What People Are Asking.