
Key Takeaways
- Scaled content operations break structurally when a single senior strategist can no longer review every asset, typically past 20 accounts, causing E-E-A-T signals to erode 1, 2.
- Rising B2B content budgets and AI adoption are pushing quality expectations higher, making outdated freelance-only workflows more expensive to run than modernized structured systems 3, 11.
- Track hours of strategist judgment per asset rather than raw output, because Google's raters detect the presence or absence of senior influence on the argument 1, 2.
- Any scaled operation needs structured stages, intent-based clustering, SERP-fit depth, a dedicated editor, and vertical brief templates before layering on advanced capabilities 4, 5, 7.
- Use E-E-A-T defensibility as a hard exclusion filter: without a documented experience-capture step per topic cluster, the model fails regardless of cost efficiency 1, 2, 10.
- Treat AI search visibility as brief-stage requirements—clear claims, entity definitions, and citable first-hand evidence—rather than a separate service bolted on afterward 10, 11.
- Compare production models on senior hours per asset, E-E-A-T defensibility, AI visibility, and cost; only in-house pods and AI-augmented approval workflows sustain oversight past 40 accounts 8, 9, 11.
- Portfolio bottlenecks shift with scale: talent at 20 accounts, QA separation at 50, and automated outcome reporting at 100 that survives enterprise procurement review 5, 10, 11.
Where scaled content operations actually break
The failure mode is not writing quality, but the point at which a single senior strategist can no longer maintain oversight on every asset. Most agency content operations function adequately with 8 to 12 accounts, where a head of SEO can review briefs, spot-check drafts, and address E-E-A-T gaps. However, when the account list exceeds 20, the review queue becomes unmanageable, leading to reduced oversight. This often results in content that feels generic, impacting rankings and client retention.
This breakdown is structural. Google's raters prioritize first-hand experience, originality, and demonstrable skill when assessing page quality 1, 2. This standard requires significant senior attention and deteriorates without it. Guides on scaling SEO content production emphasize structured stages, editorial review, and clear guidelines as crucial elements 5—components that are often the first to suffer when a strategist's time is stretched thin.
Freelance networks also reach their capacity limits sooner than many operators anticipate. Industry advice indicates that freelancers struggle to manage high-volume, high-complexity workloads without encountering capacity and coordination issues 9.
The core question is not about choosing a vendor, but about identifying a production model that sustains high senior judgment per published asset while simultaneously reducing variable costs per asset. Understanding what breaks first in the absence of such a model is key.
The market conditions forcing a production model rebuild
Two simultaneous trends are reshaping the content production landscape, rendering previous models obsolete.
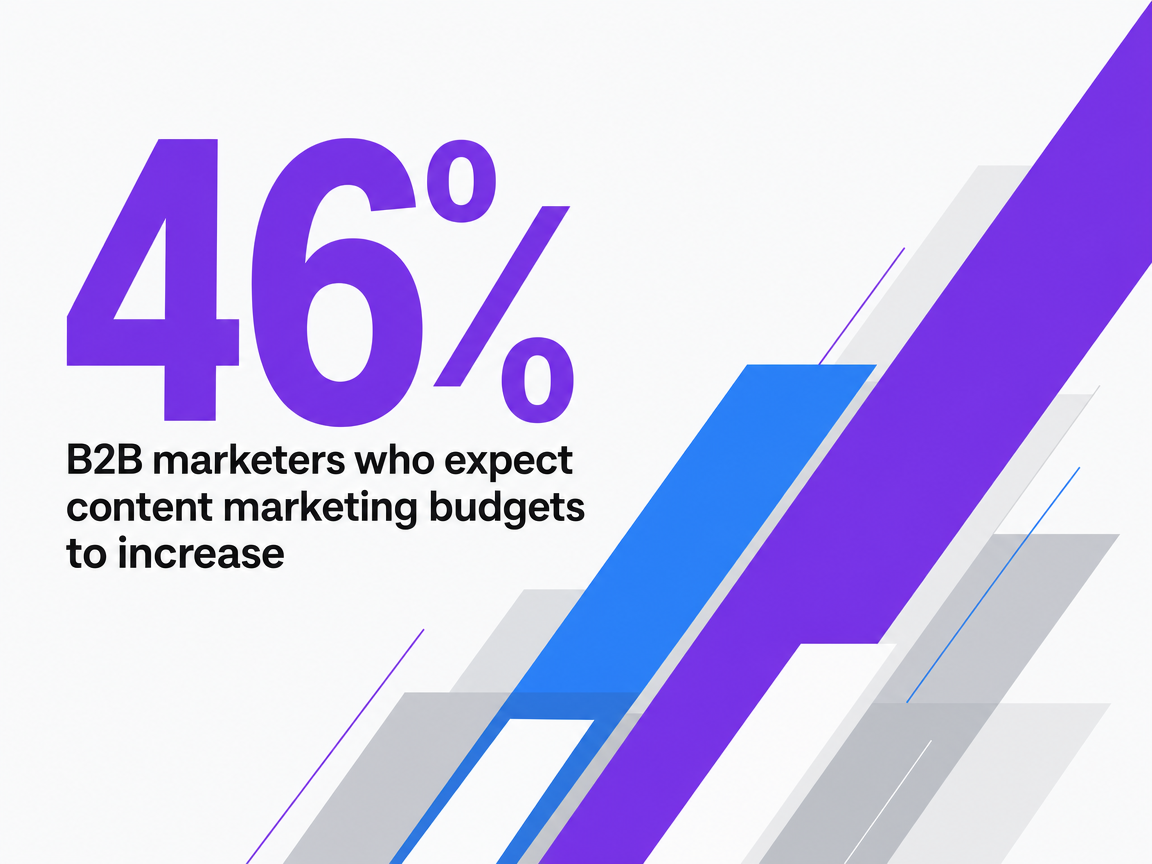
Firstly, content marketing budgets are increasing. A 2024 survey of over 1,000 global B2B marketers revealed that 46% expect budget increases in 2025, with over 70% adopting AI for content tasks 3. This indicates that additional budget is being allocated not merely for increased volume, but for greater depth and quality that AI alone cannot deliver. Top performers continue to attribute their success to audience understanding and high-quality content 3.
Secondly, the quality bar for content is rising. Google's raters emphasize first-hand experience, originality, and demonstrable skill in their page quality evaluations 1, 2. This elevated standard demands more from scaled operations to maintain or improve search performance.
The 2026 enterprise evaluation frameworks reflect this shift, treating pod team structures, outcome-based reporting, and AI search optimization as essential requirements rather than competitive advantages 11. Agencies still relying on traditional freelance models and basic collaboration tools are now competing with those who have adopted structured workflows and integrated tooling.
Consequently, adding a new client to an outdated production system now incurs higher senior review costs than it did previously. Conversely, a modernized system can absorb more output at a more stable cost. This growing disparity highlights why a re-evaluation of content production models is critical for heads of SEO.
 B2B marketers who expect content marketing budgets to increase
B2B marketers who expect content marketing budgets to increase
B2B marketers who expect content marketing budgets to increase
The senior oversight ratio: the real quality lever
The senior oversight ratio, defined as the hours of strategist judgment applied per published asset, offers a more precise measure of content quality than simply debating quantity. A head of SEO can realistically dedicate three to five hours of judgment per asset, covering brief calibration, outline review, draft critique, SERP-fit checks, and final approval. This ratio is sustainable for a portfolio of 12 clients producing four assets monthly. However, with 40 clients and the same output cadence, this ratio plummets to under 30 minutes per asset unless the production process automates mechanical tasks.
This reduction in oversight is precisely what Google's raters are trained to identify. Page quality evaluations prioritize first-hand experience, originality, and demonstrable skill 1, 2—signals that are only present when a senior operator has genuinely influenced the content's argument, not just approved a checklist. A brief informed by an interview with a client's practice lead will inherently differ from one generated solely from a keyword tool, and these differences are implicitly recognized by Google's evaluation systems.
Therefore, the key is not to produce more or less content, but to safeguard the strategist's time dedicated to critical judgment. Non-judgmental tasks—such as keyword clustering, outline scaffolding, on-page optimization, internal link mapping, and publishing mechanics—should be integrated into structured stages that do not require senior attention 5.
Operators who explicitly monitor this ratio make different decisions than those focused solely on cost per asset. They are willing to pay more per asset if it increases senior hours per asset and will terminate client relationships where account economics force the ratio below an acceptable threshold. They prioritize workflows that yield cleaner drafts over freelance rosters that consume excessive review time, recognizing that a strategist's marginal hour is the most valuable and scarce resource.
The crucial metric to track is not monthly asset output, but the ratio of senior judgment hours to that output, monitored per account and across the entire portfolio, and rigorously defended as the operation expands.
Production standards any scaled operation must clear
Before evaluating any content production model, an operator must establish a baseline of non-negotiable standards. Without these, an operation is merely busy, not truly scaled.
SEO remains a critical B2B channel, with 33% of B2B marketers identifying it as their top lead generation source. The average Google page-one result is approximately 1,447 words 4. These statistics set the expectation for content depth and channel effectiveness: clients expect content that surpasses typical SERP quality, not merely mimics it.
A scaled operation must adhere to five compounding production standards:
- The first is a structured stage model—research, writing, optimization, publishing—with clear ownership at each transition point 5. Relying on informal Google Docs or ad-hoc Slack briefs is unsustainable beyond 20 accounts, leading to asset stagnation, lost revisions, and strategists being burdened with coordination tasks unrelated to judgment.
- The second is keyword clustering based on intent, rather than solely on volume. Long-tail, high-intent keywords consistently drive better engagement and conversions than broad head terms 7. Operations that continue to brief based on raw search volume risk producing content that ranks but fails to convert.
- The third is content depth tailored to SERP context, not a predefined minimum word count. While the average page-one result is 1,447 words, this is a median, not a target 4. Some queries require concise 800-word answers, while others demand 2,600 words with original data. Word count should be determined by SERP analysis during the outline stage, not by a template.
- The fourth is a dedicated editorial review stage with its own owner, distinct from the writer's self-review 5. When review is conflated with writing, quality is limited by the writer's individual capabilities.
- The fifth is a documented style guide and brief system customized for each client vertical. A brief for a dental DSO should not be interchangeable with one for a SaaS company. Vertical-specific brief templates enable junior writers to produce high-quality drafts that approach senior-level standards.
An operation meeting all five of these standards is not yet exceptional, but it is positioned to compete effectively. All subsequent considerations—E-E-A-T defensibility, AI search visibility, and revenue-linked reporting—presuppose that this foundational level is already established.
Test AI-driven SEO content at agency scale
Experience hands-on production of publish-ready SEO content for your client portfolio—no commitment required.
E-E-A-T defensibility as an exclusion filter
Before evaluating any production model on cost or capacity, it must first pass a critical filter: its ability to withstand an E-E-A-T audit at portfolio scale. Google's raters assess page quality based on the creator's first-hand experience, alongside expertise, authoritativeness, and trust 1. The 2022 inclusion of "experience" was significant, explicitly elevating content from individuals who have directly used a product, treated a patient, or handled a case, over content merely synthesized from other search results 2. This change effectively renders the offshore content factory model unsustainable for scaled operations.
A production model either provides a clear path to demonstrating first-hand experience for each client vertical, or it does not. This is a non-negotiable requirement.
Three common failure patterns emerge during E-E-A-T audits:
- Generic writer rotation, where general-interest freelancers are assigned to diverse accounts like legal, dental, and behavioral health based solely on availability.
- AI-only drafting without subject-matter expert input, which produces plausible but unoriginal text lacking the demonstrable skill raters look for 1.
- The use of outsourced content mills, which the 2026 enterprise evaluation guidance explicitly identifies as a disqualifying vendor pattern 10.
The solution is not more editing, but a documented experience-capture step integrated into the brief stage. This could involve a 20-minute interview with the client's practice lead, a case-file review, or a product walkthrough, captured once per topic cluster and referenced across all related assets. Models unable to support this step at scale will fail the E-E-A-T filter, regardless of their cost per asset.
AI search visibility as a production requirement
Content production now serves a second crucial audience: the language models B2B buyers use to compile shortlists before engaging with human sales representatives. The 2026 enterprise evaluation guidance, citing Forrester research, notes that 94% of B2B buyers now use AI in their purchase decisions. It considers an SEO partner lacking AI search visibility methods as having "an incomplete picture" 10. This highlights why AI citation optimization has transitioned from an experimental concept to a fundamental production requirement. The same 2026 framework deems AI SEO capabilities for platforms like ChatGPT and Perplexity "non-negotiable" 11.
The impact on the production layer is more focused than many agency operators assume. It doesn't necessitate a complete overhaul of the content model, but rather a series of drafting and structural decisions that influence whether an asset is cited by a language model when summarizing a query relevant to the client's category.
Three production adjustments are particularly impactful:
- First, claim structure. Language models tend to cite passages that present a distinct claim, attribute it to a source, and position it for easy scanning—such as in an early paragraph, a list item, or a sentence adjacent to a heading. Assets structured as lengthy narrative essays with embedded assertions are less likely to be quoted than those that highlight claims within the top third of the page. This needs to be a brief-stage decision, not a post-production edit.
- Second, entity clarity. When summarizing queries like "best options for [client vertical] in [region]," language models rely on pages that clearly name the entity, define its category, and link it to specific attributes without ambiguity. Vertical-specific brief templates, already essential for E-E-A-T defensibility, can address this by including an entity-definition block for each topic cluster.
- Third, the citation-worthiness of the underlying evidence. Original data, direct interviews, and first-hand experience are the types of signals language models prioritize when synthesizing answers. These are the same signals Google's raters emphasize under the "experience" dimension of E-E-A-T 1, 2. A production model that already incorporates interviews with client practice leads for E-E-A-T defensibility will inherently produce AI-citable assets. A model that does not cannot simply add this capability later.
The implication for operators is that AI search visibility is not a separate service to offer. Instead, it represents a set of brief-stage requirements that the production stack must consistently meet for every asset.
Four production models compared on the numbers that matter
This comparison is tailored for agency operators managing 10 or more concurrent client accounts, as solo practitioners and single-brand in-house teams face different constraints.
Four dominant production models exist, each with distinct profiles across key metrics that determine the sustainability of a scaled operation: monthly asset capacity per senior strategist, senior oversight hours per asset, E-E-A-T defensibility, AI search visibility support, and relative cost per asset. Costs are indexed against a freelance-network baseline of 1.0x due to market variations in dollar figures 8, 9, 11.
| Production model | Assets/mo per senior | Senior hrs per asset | E-E-A-T defensibility | AI search visibility | Relative cost/asset |
|---|---|---|---|---|---|
| In-house pod | 20–30 | 3.0–4.5 | High | Yes, if built in | 1.6x–2.2x |
| Freelance network | 15–25 | 1.5–2.5 | Low to Medium | Partial | 1.0x (baseline) |
| Subcontracted agency | 25–40 | 0.5–1.5 | Low | Partial | 1.2x–1.8x |
| AI-augmented approval workflow (e.g., Vectoron) | 60–100+ | 1.5–3.0 | High, if experience-capture is enforced | Yes, structural | 0.5x–0.8x |
Ranges reflect operator benchmarks synthesized from outsourcing and enterprise evaluation guidance 8, 9, 11. Cost indexed to freelance-network baseline.
The in-house pod model maximizes senior oversight but is constrained by the strategist's available time. It achieves high E-E-A-T defensibility because pod members directly interview client practice leads. However, its fully-loaded compensation leads to a high cost per asset.
The freelance network is the most cost-effective per asset but offers the least defensibility at portfolio scale. Freelancers often struggle with high-volume, high-complexity workloads, leading to coordination gaps 9. The use of generic writer rotation is specifically identified as a disqualifying pattern in the 2026 enterprise evaluation guidance 10.
A subcontracted agency's performance is limited by its subcontractor's capabilities. Senior oversight is typically minimal, often insufficient to meet experience-first rater standards 1, 2.
The AI-augmented approval workflow, exemplified by Vectoron, fundamentally changes the economics. Mechanical production tasks—clustering, outlining, drafting, on-page optimization, and publishing—are managed through a structured stage model without consuming strategist time 5. Every asset undergoes a mandatory senior approval checkpoint before publication, ensuring oversight remains within a defensible range. This model can increase capacity per strategist by three to five times compared to the pod model. Its E-E-A-T defensibility depends on whether it enforces an experience-capture step during the brief stage; models that omit this will fail audits regardless of throughput.
Ultimately, the critical metrics are not isolated asset volume or cost, but their ratio to the applied senior judgment. Only two of these four models can sustain this ratio effectively when managing over 40 accounts.
Scale SEO Content Delivery Without Expanding Your Team
Connect with experts to see data-backed workflows for automating high-volume, multi-client SEO content production—while maintaining the strategic oversight and quality your agency demands.
If you manage 20, 50, or 100 client portfolios
This section is for agency operators whose client list has grown beyond the point where a single senior strategist can personally oversee every asset. The challenges and solutions vary significantly with portfolio size.
At 20 accounts, the primary breakdown is talent. The freelance roster that sufficed for the first ten clients begins to produce drafts that meet basic checklists but fall short of Google's experience-first standard 2. The head of SEO spends excessive time rewriting instead of approving. The necessary adjustment is structural: offload mechanical tasks—such as clustering, outline scaffolding, and on-page optimization—from the writer, allowing them to focus their time on the judgmental aspects of the draft. Simply adding more freelancers will not resolve a coordination problem 9.
At 50 accounts, the bottleneck shifts to QA. Editorial review often becomes a single point of failure managed solely by the strategist, and structured stages that worked at 20 accounts collapse under the increased volume of handoffs 5. The solution is to separate the approval checkpoint from the actual editing labor. Approval remains with the senior strategist, while editing becomes a distinct stage with its own owner and service level agreement. Portfolios that fail to implement this separation risk shipping lower-quality drafts under senior initials, a pattern the 2026 enterprise evaluation guidance identifies as a sign of an operation exceeding its capacity 10.
At 100 accounts, the critical issue is reporting. Content is being published, rankings are fluctuating, but attributing portfolio-wide outcomes to specific decisions requires extensive manual data extraction. The solution must be implemented upstream: the production stack needs to automatically generate approval, publication, and performance data as a natural byproduct of the workflow, rather than requiring a separate reporting project. Operations attempting to reach this scale with a stack designed for 20 accounts will not pass the initial procurement review from an enterprise client.
Reporting standards that survive procurement review
Enterprise procurement teams do not rely on ranking screenshots. The 2026 evaluation frameworks now assess agencies based on outcome-based reporting linked to revenue, rather than traffic metrics, and require sample reference-client reports during the RFP stage 11. A production stack unable to provide this data on demand will lose accounts it should have retained.
Three reporting standards distinguish operations that succeed in procurement reviews from those that face contract non-renewal:
- First, revenue attribution at the asset level. Reports must demonstrate which published pieces directly contributed to pipeline movement, not just which ones generated impressions. The 2026 enterprise guidance explicitly states that vanity metrics are no longer sufficient and that outcome linkage is the primary criterion 11.
- Second, AI search visibility as a tracked metric. This includes citation frequency across platforms like ChatGPT and Perplexity for target queries, reported alongside traditional SERP position 10. Procurement teams now consider reports lacking this data incomplete.
- Third, approval and production telemetry. This includes data on which assets shipped, which strategist approved them, and the current stage of each asset 5. Portfolios unable to generate this information clearly are operating without full insight into their own processes, a fact easily discernible by enterprise buyers within one reporting cycle.
 B2B buyers who use AI during purchase decisions
B2B buyers who use AI during purchase decisions
B2B buyers who use AI during purchase decisions
Designing the stack you actually want to run
The strategic move for operators is not to simply choose a vendor category, but to design a production stack where senior judgment is the only scarce resource. All other tasks—clustering, drafting, on-page optimization, publishing, and reporting—should be managed through structured stages that do not consume the strategist's time 5.
Three core design commitments are essential:
- Enforce an experience-capture step at the brief stage for each topic cluster, as failure to do so will lead to E-E-A-T audit failures regardless of throughput 1, 2.
- Route every asset through a single, mandatory senior approval checkpoint to maintain a defensible oversight ratio as accounts scale.
- Ensure that approval, publication, and outcome data are automatically generated as byproducts of the workflow, rather than requiring a separate reporting project 11.
Operations successfully managing over 40 accounts share a common characteristic: they treat AI-augmented approval workflows, such as Vectoron, as essential production infrastructure, not merely a vendor replacement. The strategist remains the critical bottleneck, and the entire system is rebuilt to protect and optimize their valuable time.
 B2B marketers using AI for content tasks
B2B marketers using AI for content tasks
B2B marketers using AI for content tasks
Frequently Asked Questions
References
- 1.Search Quality Rater Guidelines: An Overview.
- 2.Our latest update to the quality rater guidelines: E-A-T gets an extra E for experience.
- 3.B2B Content Marketing Benchmarks, Budgets, and Trends: Outlook for 2024.
- 4.B2B Marketing Benchmarks: Measuring Your Success in 2024.
- 5.Scale SEO Content Creation Without Compromising Quality.
- 6.Quality or Quantity? Content Creation for SEO.
- 7.Quality Or Quantity: Which is Better for SEO?.
- 8.SEO In House vs Outsourcing: What To Choose For SaaS in 2026.
- 9.Outsourcing SEO: Decision-Making Guide.
- 10.Enterprise SEO Company: Evaluation Guide 2026.
- 11.Best Enterprise SEO Agency Guide: The 2026 Evaluation Framework.