
Key Takeaways
- Treat SEO copywriting selection as procurement, not creative preference, using a weighted four-axis scorecard so every vendor, in-house build, and AI platform gets graded on identical rows 13.
- Fix scorecard weights before any sales call, drawing sub-criteria from outside standards rather than vendor decks so the loudest pitch cannot redefine the evaluation criteria mid-process.
- Grade readability on documented process—reading-level checks, comprehension review, audience testing—since most published health and legal content sits well above the level general readers can use 5.
- Demand technical SEO artifacts including twelve-month audit logs, descriptive anchor style guides, and retirement lists, because scheduled updates and descriptive links separate systems from one-time deliverables 10, 11.
- Score governance on intake templates, QBR samples, editorial policies, and correction workflows in writing, since quality variance across the category concentrates risk on the buyer when controls are absent 6.
- Measure cost per published, ranked, converting page across the asset's useful life, which typically lands two to four times higher than the retainer-divided-by-articles figure vendors quote.
- For multi-location operators, stress-test whether the vendor's briefing cadence, refresh discipline, and reporting model hold at the actual location count before signing, not after rollout begins 13.
- Move the short list through governance and unit economics with live materials—filled templates, cohort reports, sample QBRs—and let missed deadlines on those requests self-select vendors out.
Why SEO Copywriting Belongs in Procurement, Not Marketing Taste Tests
A marketing VP at a 40-location dental group inherits three SEO copywriting vendors, two overlapping retainers, and a CFO asking why organic traffic has flatlined for six quarters. The instinct is to pick a favorite writer sample and consolidate. The correct move is to run a procurement process.
SEO copywriting sits at the intersection of service quality, findability, and compliance risk. Digital.gov frames strong search performance as the mechanism that lets audiences "navigate complex programs, and find the information they need quickly"—positioning copy quality as a service outcome, not a branding exercise 1. For law firms, DSOs, behavioral health groups, and senior living operators, that reframe matters. The content ships into regulated conversations where misreading has consequences.
Vendor selection guidance from the Small Business and Technology Development Center is explicit: business owners should evaluate how agencies set requirements, report cadence, and prioritize metrics 13. Those are procurement questions, not creative ones.
The rest of this guide builds a four-axis scorecard—readability rigor, technical SEO fluency, governance and reporting, and unit economics per published page—and forces every candidate through the same sheet. That includes traditional agencies, in-house hires, and AI production platforms. The output is a defensible recommendation, not a preference.
The Four-Axis Scorecard: What You Are Actually Grading
Building a Weighted Model Before You Take a Sales Call
A defensible scorecard fixes its axes before any vendor demo. Otherwise the loudest sales deck sets the criteria. Four axes cover the ground a marketing VP can defend to a CFO: readability rigor, technical SEO fluency, governance and reporting, and unit economics per published page.
Each axis needs sub-criteria drawn from outside sources, not vendor pitch decks. Readability rigor pulls from CDC plain-language standards, which treat clear structure and audience testing as baseline requirements for materials aimed at the general public 2. Technical SEO fluency draws from Michigan Tech's guidance on authoritative content and scheduled updates 10 and the Department of Energy's standards on descriptive internal links, alt text, and routine removal of outdated pages 11. Governance and reporting borrows the SBTDC framework: how the vendor sets requirements, how often it reports, and which metrics it prioritizes 13. Unit economics is the finance lens the other three feed into.
Weight the axes before the first call. A behavioral health group with FTC scrutiny may weight governance at 30 percent. A home services franchise with weak organic share may weight technical SEO higher. The weights are the argument.
Grading Every Candidate on the Same Sheet, Including AI Platforms and In-House Builds
The scorecard only holds up if every option runs through it. That means the incumbent agency, the two challengers pitching for the account, an in-house writer plus editor build, and any AI content platform under review all get graded on the same rows.
Treating AI platforms as a peer category is the change most evaluation guides skip. Peer-reviewed work on the DISCERN tool shows AI is now used to assess content quality, not only produce it, which forces a broader definition of what a copy vendor can be 4. An in-house build deserves the same treatment. Salary, benefits, tooling, editor time, and ramp-up all belong in the unit economics row alongside any retainer.
Score each row 1 to 5 with a written justification. A candidate that cannot describe its readability testing process scores a 1 on that row, regardless of writing samples. A candidate that publishes to a CMS but cannot demonstrate descriptive internal linking or alt-text discipline scores low on technical SEO 11. The scorecard replaces impression with evidence, and the winner is whichever column posts the highest weighted total.
 Visualize the four evaluation axes framework introduced in this section as a scorecard structure, giving readers a reference model for the rest of the article
Visualize the four evaluation axes framework introduced in this section as a scorecard structure, giving readers a reference model for the rest of the article
Axis One: Readability Rigor for Regulated Audiences
The Understand-It-The-First-Time Standard
The strongest readability benchmark available to a marketing VP is also the simplest to defend in a boardroom: readers should understand the content the first time they read it. Duke's health literacy guide states that plain language is communication an audience can understand on first read or first hearing 3. That single sentence eliminates most of the debate about tone, voice, and reading level.
The CDC operationalizes the standard with three demands on any content team:
- use simple words,
- structure information so readers can scan and act, and
- test drafts with the actual audience before publishing 2.
Any SEO copywriting agency should be able to walk through each of those steps with named tools, sample outputs, and a documented review path. Vague references to "writing for humans" or "conversational tone" do not clear the bar.
Grade this row on process, not preference. A candidate that ships copy without a documented reading-level check, a comprehension review, or an audience testing loop scores low regardless of how polished the samples read. User expectations align with the same standard—research on how people use the internet for health information finds that audiences expect content to be accurate, understandable, and current 8. Those three words become scorecard sub-criteria.
How Far Real-World Copy Falls Short
The evidence on published content sets a low bar for competitors, which makes it easier to spot a serious agency. A systematic review of health-related websites concluded that most sites are written above the recommended reading level for the general public, limiting who can actually use the information they contain 5. Public health authorities generally recommend material at roughly a sixth- to eighth-grade reading level, while the sites analyzed skewed closer to eleventh grade and above.
That gap is the reference chart a marketing VP should pin next to any writing sample under review. If the review found this pattern across an entire category, incumbent agencies producing content for behavioral health groups, senior living operators, or DSOs are statistically likely to be shipping copy above the useful range. The review also flagged limitations in common readability formulas, which is why grading should combine an automated score with a short comprehension test on live audiences 5.
Practical scoring: pull five recent published pages from every candidate. Run each through a readability tool. Ask the agency what the target grade level was, how it was set, and how it is monitored across quarterly content refreshes. Candidates that cannot answer those three questions are grading themselves out of the readability row.
Vertical Stakes: Law, Behavioral Health, DSOs, Senior Living
Readability failure carries different costs in different verticals, and the scorecard weight should reflect that. For law firms, a review of online legal information found that resources aimed at the public often lack clear explanations, which raises the risk of misinterpretation and misapplication by readers making real decisions 9. An agency writing personal injury or estate planning pages needs to demonstrate how it simplifies without stripping legal accuracy—a specific skill, not a generic writing trait.
Behavioral health and senior living copy sits closer to the CDC's plain-language territory, where the standard is framed as essential for equitable access and safe decision-making rather than stylistic preference 2. Adult children researching memory care for a parent, or a patient scanning intake pages for an outpatient program, cannot afford to reread a paragraph three times. DSOs face a related pattern: procedure explanations that miss lay comprehension push more traffic into the call center rather than the appointment book.
Weight the readability axis higher for candidates serving these verticals. A general-purpose agency that scores well on B2B SaaS samples has not proven it can carry regulated audiences through complex decisions on first read.
Test ROI-Driven SEO Content Execution Yourself
Publish live SEO-optimized content and measure pipeline impact before making a commitment.
Axis Two: Technical SEO Fluency Beyond Keyword Lists
Authority, Freshness, and Descriptive Link Architecture
Keyword targeting is table stakes. The technical SEO axis grades whether an agency treats copy as a system that ages, links, and gets audited—not a one-time delivery.
Michigan Tech's guidance lists two habits as central to ranking durability: publishing relevant, authoritative content and updating that content on a schedule 10. A candidate should be able to describe its authority-building process in specifics. Which subject-matter reviewers sign off on a personal injury landing page before it publishes? How does a memory care service page get refreshed when state regulations change? A vendor that cannot name the reviewer, the refresh trigger, and the audit cadence is not doing this work.
The Department of Energy's SEO standards add two rows to the scorecard. Content should be "clear, concise, unique, and authoritative," and outdated pages should be routinely removed rather than left to decay 11. Internal links should be descriptive—anchor text that tells a reader and a crawler what sits behind the click, not "learn more" and "click here" scattered across a service footer 11.
Score the row by asking for artifacts:
- a content audit log from the last twelve months,
- a link-anchor style guide, and
- a retirement list of pages pulled or consolidated.
Vendors that cannot produce these are selling deliverables, not a system.
Accessibility as an SEO Signal, Not a Side Project
Accessibility and SEO overlap more than most agencies price into their retainers. The Department of Energy's standards explicitly tie SEO practice to Section 508 compliance, calling out alt text on images as both an accessibility requirement and a search signal 11. For a senior living operator or a behavioral health group, that overlap is not a bonus—it is a legal and operational baseline the copy vendor either meets or does not.
Grade this row on documented practice. Does the agency write alt text as part of the copy deliverable, or does it hand off images without any descriptive text? Does it structure headings so screen readers can traverse the page? Are PDFs and downloadable intake forms produced with tagged structure and readable order?
A candidate that treats accessibility as a developer's problem after the copy ships scores low here. The vendors that treat clarity, alt text, and heading structure as part of the same craft tend to score high across the readability and technical rows both—the disciplines reinforce each other rather than compete for hours.
Axis Three: Governance, Ethics, and Reporting Transparency
Intake, Requirements-Setting, and Reporting Cadence
Governance starts before the first article ships. The SBTDC framework for evaluating SEO partners centers three questions: how the agency sets requirements, how often it reports, and which metrics it prioritizes 13. A vendor that cannot answer all three in the first meeting is not ready to be scored.
Requirements-setting is the intake discipline. A serious agency walks in with a documented process for capturing target audience, service-line priorities, geographic footprint, conversion definitions, and the KPIs that determine whether a page earned its slot. A weak agency asks for a keyword list and a brand guide, then disappears for six weeks. The difference shows up on the scorecard as either a documented intake artifact—a filled requirements template with sign-off fields—or its absence.
Reporting cadence deserves the same specificity. Monthly PDFs with rank tracking are not reports; they are dashboards printed as documents. Grade the row on three sub-criteria: frequency, metric hierarchy, and decision output. A quarterly business review that ends with a ranked list of content refreshes, retirements, and new commissions is a report. A screenshot of Google Search Console with a paragraph of commentary is not. Ask each candidate for a sample QBR deliverable and score what actually gets sent to clients, not what the pitch deck promises.
Conflicts, Disclosures, and the Quality-Variance Problem
Ethics belongs on the scorecard because quality across the category is uneven. A review of online health information found the quality of published content "highly variable," which puts governance controls squarely on the buyer when outsourcing production 6. Contracting with an agency does not transfer that risk—it concentrates it.
The ethical criteria are concrete, not abstract. Content aimed at patients, clients, or residents should support informed decision-making rather than push a preferred service line, and disclosure of any commercial relationship shaping the copy should be visible to the reader 7. For a behavioral health group or a senior living operator, that translates into contract language: who reviews claims, how outcome data is characterized, and what happens when a service change requires retracting or amending live pages.
Score this row by asking for the agency's editorial policy in writing. Does it name a fact-checking process? A conflict-of-interest disclosure procedure? A correction workflow with defined turnaround? A candidate that has none of these documented is asking the client to absorb every quality-variance event that reaches the live site. Vendors with mature policies typically produce them within a day; the delay itself is a data point.
Where AI Assessment Fits in Your QA Loop
AI now sits on both sides of the content workflow—production and evaluation. Peer-reviewed work on the DISCERN tool tested whether a large language model could assess the quality and readability of online health information, finding real capability alongside meaningful limits that argue for combining automated scoring with expert review 4.
The practical read for a marketing VP is that the QA loop should include an automated pass and a human pass, and the scorecard should reward vendors that already run both. Automated checks catch reading level drift, missing alt text, thin word counts, and internal-link gaps at scale. Human review catches the claims that read fine to a machine and wrong to a subject-matter expert.
Ask each candidate what runs automatically on every draft, what a human reviewer signs off on, and where the two records live. An agency that cannot separate machine QA from expert QA is running one of them on faith.
Axis Four: Unit Economics Per Published, Ranked, Converting Page
The finance-defensible unit for SEO copywriting is not cost per word, cost per article, or cost per retainer month. It is cost per published, ranked, converting page—measured across the useful life of the asset. That metric collapses production spend, revision cycles, technical hygiene, and content decay into a single number a CFO can compare against paid channels.
Build the denominator from three filters applied in sequence:
- Published means live on the site with correct metadata, descriptive internal links, and alt text in place 11.
- Ranked means holding a position that generates non-branded organic sessions for at least two consecutive quarters, which requires the scheduled updates and authority signals a serious vendor should already be delivering 10.
- Converting means producing a defined action—qualified call, booked consult, intake form, tour request—tracked back to the URL.
Most agencies quote the numerator only. A $9,000 monthly retainer producing eight articles reads as $1,125 per piece. Apply the three filters and the honest figure often lands two to four times higher, because a share of the output never ranks or never converts. The SBTDC framework treats metric prioritization as a core evaluation criterion for that reason: vendors that cannot report against business outcomes are pricing against activity 13.
Score this row on whether each candidate can produce a cohort report showing what percentage of the last twelve months of output currently ranks, converts, and still meets the readability and technical rows above. Vendors that decline the exercise are answering the question.
See How AI-Driven SEO Copywriting Outperforms Traditional Agencies
Request a data-backed comparison of your current SEO copywriting workflow versus AI-powered execution—quantifying efficiency, content quality, and measured pipeline impact for enterprise-scale teams.
If You Manage Multiple Locations: Consolidation Economics
The scorecard math shifts when a single VP owns organic pipeline across twenty, forty, or two hundred locations. Briefing overhead, template governance, and time-to-publish behave differently at that scale, and the unit economics row changes with them.
At one location, a retainer that produces eight solid pages a month can look reasonable. At forty locations, that same production rate leaves most service pages stale, most geo-modifier variants unbuilt, and the content refresh cadence that Michigan Tech treats as central to ranking durability effectively abandoned 10. The Department of Energy's standard on routinely retiring outdated pages becomes an operational headache rather than a hygiene check when each location has its own drift 11.
A comparative view helps isolate where each vendor archetype breaks under multi-location load. The rows below use variables where sourced dollar figures do not exist; the operator plugs in current retainer and salary numbers to run the model.
| Criterion | Traditional SEO copywriting agency | In-house hire | AI-assisted content platform |
|---|---|---|---|
| Monthly fixed cost | Retainer $X per month | Salary + benefits + tooling $Y | Platform fee $Z |
| Briefing hours per asset | Higher; per-location intake cycles | Moderate; internal context reused | Lower; template + data reused across locations |
| Revision cycles | 2–3 rounds standard | 1–2 rounds internal | 1 round on approval workflow |
| Time-to-publish | Weeks per batch | Days to weeks | Days, gated by human approval |
| Governance model | Vendor-defined; report cadence varies 13 | Direct oversight; single reviewer bottleneck | Approval-first with logged reasoning |
Score the row on whether the model holds at the operator's actual location count. SBTDC's evaluation questions on requirements-setting and reporting frequency compound with each location added—a vendor that runs one intake cycle per city does not scale to a forty-site rollout without pricing that up materially 13.
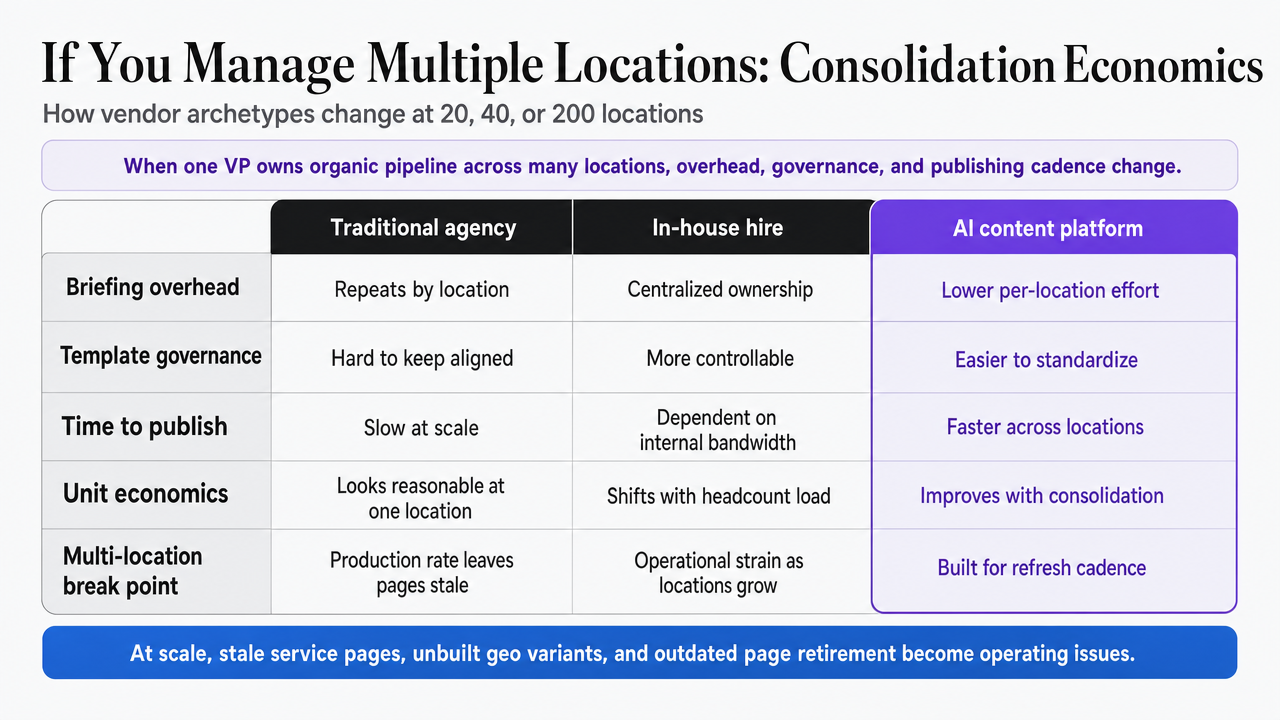 Render the article's comparison table of three vendor archetypes (traditional agency, in-house hire, AI content platform) as a visual side-by-side matrix so multi-location operators can scan the tradeoffs at a glance
Render the article's comparison table of three vendor archetypes (traditional agency, in-house hire, AI content platform) as a visual side-by-side matrix so multi-location operators can scan the tradeoffs at a glance
Running the Scorecard: From Long List to Defensible Recommendation
The scorecard becomes a decision document when a VP walks it into the room with weights set, artifacts collected, and rows scored 1 to 5 with written justification. Start with a long list of five to seven candidates spanning all three archetypes—traditional agency, in-house build, AI content platform—and cut to a short list of three by scoring the readability and technical rows first. Those two axes eliminate the vendors that cannot produce artifacts on request, which is most of them.
Move the short list through governance and unit economics with live materials, not pitch decks. Request:
- a filled requirements template,
- a sample QBR,
- a twelve-month content audit log, and
- a cohort report showing what percentage of prior output still ranks and converts 13.
Vendors that miss the deadline on these requests are self-selecting out. Confirm each candidate's editorial policy, correction workflow, and disclosure procedure in writing before final scoring 7.
The winning column is whichever posts the highest weighted total across all four axes—not the strongest single row. Present that total to finance with the sub-scores and artifacts attached. If an AI-assisted platform tops the sheet, the same evidence supports the decision; Vectoron builds this scorecard logic into its approval workflow so the reasoning is logged with every published page.
Frequently Asked Questions
References
- 1.Search engine optimization | Digital.gov.
- 2.Plain Language Materials & Resources | Health Literacy.
- 3.Health Literacy: Plain Language.
- 4.ChatGPT's Ability to Assess Quality and Readability of Online Health Information Using the DISCERN Tool.
- 5.Readability of health-related websites: a systematic review.
- 6.Quality of Online Health Information: Update on the State of the Art.
- 7.Ethical Issues in Online Health Information.
- 8.Internet Use and Expectations for Online Health Information.
- 9.Online Legal Information: Quality and Accessibility.
- 10.Six Ways to Improve Your Site's Ranking (SEO).
- 11.Search Engine Optimization Best Practices.
- 12.Readability of health-related websites: a systematic review.
- 13.How to Evaluate an SEO Agency.