Key Takeaways
- Score originality at scale by asking for the program's 90-day draft reject rate; a 15-30% rework rate signals real quality controls, while zero means no enforced standard against Google's originality criteria 1.
- Demand technical diagnostics that respond to core updates within days, producing segmented query and URL impact analysis with defend, consolidate, or remove decisions rather than scheduled PDF audits 2.
- Require a conversion layer on every organic page because AI Overviews compress clicks to 8% on present queries, making traffic-only deliverables a declining asset 12.
- Coordinate SEO, PPC, content, and links inside one account-level operating view so query and conversion signals move across channels in days, not weeks, eliminating the hidden in-house reconciliation tax 9.
- Measure execution velocity by median cycle times from signal to live work; programs compressing those medians land in the 39% improving cohort, not the 34% flat one 7.
Why deliverable counts stopped predicting SEO outcomes
For most of the last decade, SEO packages were sold as inventory: a fixed number of blog posts, backlinks, technical audits, and keyword targets per month. That model held up when ranking gains correlated with output volume. It no longer does. Google's 2024 integration of the Helpful Content system into its core ranking systems shifted evaluation toward site-wide usefulness rather than per-page tactics 11, and the March 2024 core update rolled out globally with broader spam-policy changes attached 10. Packages built around deliverable counts were calibrated for a ranking environment that has been retired.
The performance distribution backs this up. Conductor's 2025 research found 91% of marketers reported SEO positively impacted website performance and marketing goals in 2024 5— yet anyone managing a growth program knows results are not evenly distributed across that 91%. Some programs compound. Others stall despite identical deliverable schedules. The variance is no longer explained by how many pages shipped or how many links were built. It is explained by whether the work satisfies Google's stated criteria for original, people-first content 1and whether the program is engineered for a search surface where AI summaries increasingly sit between the user and the click.
SaaS growth directors evaluating SEO services packages in 2025 are really asking a different question: what does a defensible SEO program look like when Google's quality systems penalize scaled mediocrity and AI Overviews compress the click-through opportunity? The answer is a scoring framework, not a tier sheet. The next section introduces it.
The five-criteria scorecard for evaluating any SEO program
The scorecard below replaces tier comparisons with a diagnostic a growth director can apply to any vendor proposal, internal program, or hybrid arrangement. Each criterion maps to a specific 2024–2025 ranking system change or behavioral shift, so the framework reflects how Search actually evaluates and rewards work today rather than how packages were priced five years ago.
The five criteria are:
- Originality at scale
- Technical diagnostics tied to core update behavior
- A conversion layer engineered for AI-mediated search
- Channel coordination beyond isolated SEO
- Execution velocity measured by operational maturity
None of them appear on a standard package brochure. All of them separate programs that compound from programs that stall. A director scoring a current vendor across these five dimensions will surface the gaps that deliverable lists were designed to hide — and identify which capabilities belong inside a continuous-execution model versus a retainer cycle. The subsections that follow define each criterion, anchor it in primary evidence, and describe what passing looks like.
Criterion 1: Originality at scale, not output at scale
The first failure mode of a traditional package is treating originality as a content brief checkbox rather than a production discipline. Google's helpful content guidance is explicit that originality, demonstrated expertise, and a clear page purpose are what the ranking systems are tuned to reward, and it warns that mass-produced or search-engine-first content can trigger spam policies regardless of how polished the surface looks 1. Volume-based retainers — twelve posts a month, four pillar pages a quarter — were calibrated for a ranking environment that has been actively dismantled.
Google reported that its March 2024 ranking and policy changes reduced low-quality, unoriginal content in Search results by 45%, per the company's own stated scope of impact on its Search index 3. That figure describes what Google removed or demoted inside Search — not a market-wide content quality measurement — and it is the cleanest signal available that scaled mediocrity now carries a direct visibility cost. Programs that ship more pages than they can substantively differentiate are operating against the grain of the system that ranks them.
Originality at scale, as a scoring criterion, asks whether the package builds a defensible point of view across every asset. A passing program shows:
- Documented subject-matter inputs (interviews, proprietary data, practitioner review) feeding each piece, not just AI drafts edited for tone.
- A content brief format that specifies what new claim, dataset, or framework the piece will introduce rather than which keywords to hit.
- A quality assurance step that rejects pieces failing those tests before publication, not after a ranking drop.
Output counts can stay the same or even rise, but each unit has to clear a higher originality bar than it did under pre-2024 ranking systems.
What this looks like in package economics: a vendor or internal program that cannot describe its originality controls in operational terms — who reviews, against what criteria, with what reject rate — is selling output, not outcomes. Directors evaluating proposals should ask for the reject rate on the last 90 days of drafts. A program with a 0% reject rate is not maintaining a quality bar; it is decorating one. A program with a documented 15–30% rework or kill rate is closer to the discipline the current ranking systems reward 11. That single question separates packages built for 2018 from packages built for the search surface as it actually ranks today.
Criterion 2: Technical diagnostics tied to core update behavior
The second criterion separates technical SEO as a recurring audit deliverable from technical SEO as a live diagnostic capability. Most packages include a quarterly or annual technical audit — crawl, indexation, schema, Core Web Vitals — delivered as a PDF with a punch list. That artifact tells a director what was broken on a specific date. It does not tell the program what to do when rankings move during or after a core update.
Google's own core update documentation is direct on this point: site owners experiencing traffic drops should compare the right dates, review the specific top pages and queries affected, and evaluate whether the site is helpful, reliable, and people-first against the broader content of the page and the site 2. That is a diagnostic protocol, not an audit. It requires the program to instrument Search Console and analytics data so that query-level and URL-level shifts are visible within days of an update completing, not at the next quarterly review. The Helpful Content system's integration into core ranking in March 2024 made this even sharper, because content quality signals now move with every core update rather than as a separate scheduled refresh 11.
A passing program on this criterion shows three artifacts on demand:
- A baseline of query and URL performance segmented by intent and conversion value, not just clicks.
- A documented response protocol that triggers within a defined window after Google announces a core update.
- A prioritization rubric that distinguishes pages worth defending, pages worth consolidating, and pages worth removing.
The last item matters because Google's guidance treats site-wide quality as a ranking factor, which means underperforming thin pages can suppress otherwise strong assets on the same domain 1.
Directors auditing a current package should ask for the program's response to the most recent completed core update. A vendor that responds with general reassurance has no diagnostic layer. A vendor that responds with a segmented impact analysis, a list of pages prioritized for revision, and a measured recovery trajectory is doing the work the ranking systems now require. The same test applies to in-house teams. The deliverable is not the audit. The deliverable is the speed and specificity of the diagnostic when something moves.
Criterion 3: A conversion layer engineered for AI-mediated search
The third criterion is the one most traditional packages structurally omit. SEO retainers were designed to deliver traffic; conversion was treated as a separate CRO engagement or left to the in-house team. That separation is no longer defensible because the search surface itself now intercepts a meaningful share of clicks before they reach the site.
Pew Research data summarized by Search Engine Land found that about 18% of Google searches in March 2025 triggered an AI Overview 4. When AI Overviews appeared, only 8% of users clicked any link on the results page, and only 1% clicked one of the citation links inside the AI summary itself 12. The numbers describe a specific behavioral shift on AI-Overview-present queries — not a 92% collapse in all organic clicks — but the operational consequence for SEO programs is direct: a growing share of high-intent queries return an answer to the user without a click, and the click rate on the queries that do trigger overviews is materially compressed.
A package that produces traffic without producing converted action against this backdrop is producing a declining asset. Conversion has to be engineered into the SEO program itself, not handed off. That means three concrete deliverables belong inside the SEO scope:
- Page-level intent matching that distinguishes pages built to be cited inside an AI Overview from pages built to capture and convert the click-through that does occur.
- On-page conversion architecture — primary action, secondary capture, third-tier resource — designed for the segment of traffic that survives AI mediation.
- Owned-audience capture mechanisms (email, product trial, gated utility) on every page positioned for queries with conversion intent, because the marginal click is now too expensive to leave unconverted.
The directional implication is also that brand and entity signals matter more than they did when clicks were cheaper. When 1% of users click a citation link inside an AI Overview, the citation itself still has value as a brand impression and as a training signal for which entities the model associates with which queries — but only if the program is engineered to capitalize on the click that does happen and on the impression that does not.
Scoring a current package on this criterion is straightforward. Ask what percentage of pages produced in the last quarter were instrumented for a defined conversion event tied to pipeline, not a soft engagement metric. Ask what the program's email or trial capture rate is on organic landing pages and how that number has moved over the last two quarters. A package that cannot answer those questions is selling a 2018 deliverable into a 2025 search surface.
Criterion 4: Channel coordination instead of isolated SEO retainers
The fourth criterion tests whether the SEO program operates as a coordinated input to the broader acquisition system or as a sidecar. The traditional retainer structure — SEO agency on one contract, PPC agency on another, content agency on a third, with the in-house team holding the integration burden — was tolerable when channel performance was largely independent. It is not tolerable when intent data, query coverage, and creative testing flow across channels at weekly cadence.
Similarweb's 2025 SEO benchmarking work and its cross-channel marketing benchmark both frame current measurement around smarter spending and integrated performance views across channels rather than channel-isolated KPIs 9, 8. That direction reflects what growth directors already know operationally: SEO query data should inform paid search match-type strategy and ad copy; paid search conversion data should inform which organic pages get conversion investment; backlink targets should align with PR and partnership activity; and content production should serve both channels from a single calendar.
Coordination is not a deliverable. It is an operating model. A passing program on this criterion shows shared account-level data inputs — GA4, Search Console, Ads, and SEMrush or equivalent — feeding a single prioritization view, not four parallel ones. It shows briefs that designate which pages are paid-traffic destinations, which are organic, and which serve both. It shows weekly or biweekly cycles where SEO query expansion informs PPC keyword testing and PPC conversion data informs SEO page revision priorities.
The retainer structure actively works against this. Each agency optimizes its own scope, and coordination overhead falls on the in-house director, who absorbs the cost in calendar time and context-switching. Directors scoring this criterion should quantify that overhead honestly:
- Hours per week spent reconciling reports across vendors.
- Hours per quarter spent in cross-vendor planning sessions.
- The latency between a signal appearing in one channel and being acted on in another.
A program that drops that latency from weeks to days — through a single account-level operating layer rather than three parallel ones — is producing coordination value that no individual channel retainer can match.
Criterion 5: Execution velocity measured by operational maturity
The final criterion is the one most often mistaken for output volume. Velocity, in the context of a modern SEO program, is not how many pieces ship per month. It is how quickly the program can move from signal to decision to live, indexed, instrumented work — and how consistently it does so.
The Content Marketing Institute's current B2B research reports that 39% of respondents say their content performance improved year-over-year, 34% say it stayed flat, and 5% say it decreased, with the remainder unsure 7. The distribution is the point. Programs operating at similar output volumes are landing in materially different performance bands, which means volume is not what separates the 39% from the 34%. Operational maturity is. The programs improving have shorter cycles between research and publication, tighter feedback loops between analytics and revision, and cleaner handoffs between specialists.
Operational maturity on this criterion shows up in measurable cycle times: how many days from topic identification to brief approval, from brief to draft, from draft to publication, from publication to first measurable performance read, and from underperformance signal to revision. A traditional retainer with monthly planning calls and quarterly business reviews has cycle times measured in weeks at every stage. A continuous-execution model with daily prioritization and standing approval workflows compresses those cycles into days.
The compounding effect is what matters. A program that moves from signal to live work in 5 days versus 25 days does not produce five times the output. It produces work that reflects the most recent ranking behavior, the most recent competitor activity, and the most recent conversion data — which is a different category of asset. Over a 12-month horizon, the difference between the 39% improving cohort and the 34% flat cohort is rarely about who shipped more pages. It is about who shipped pages that reflected what the program learned in the previous 30 days.
Directors scoring this criterion should ask the program to report its median cycle time at each stage and how those medians have moved over the last two quarters. A program that cannot produce those numbers is not measuring its own velocity. A program that can — and that shows the medians compressing — is the one most likely to land in the improving band as ranking systems and search behavior keep moving.
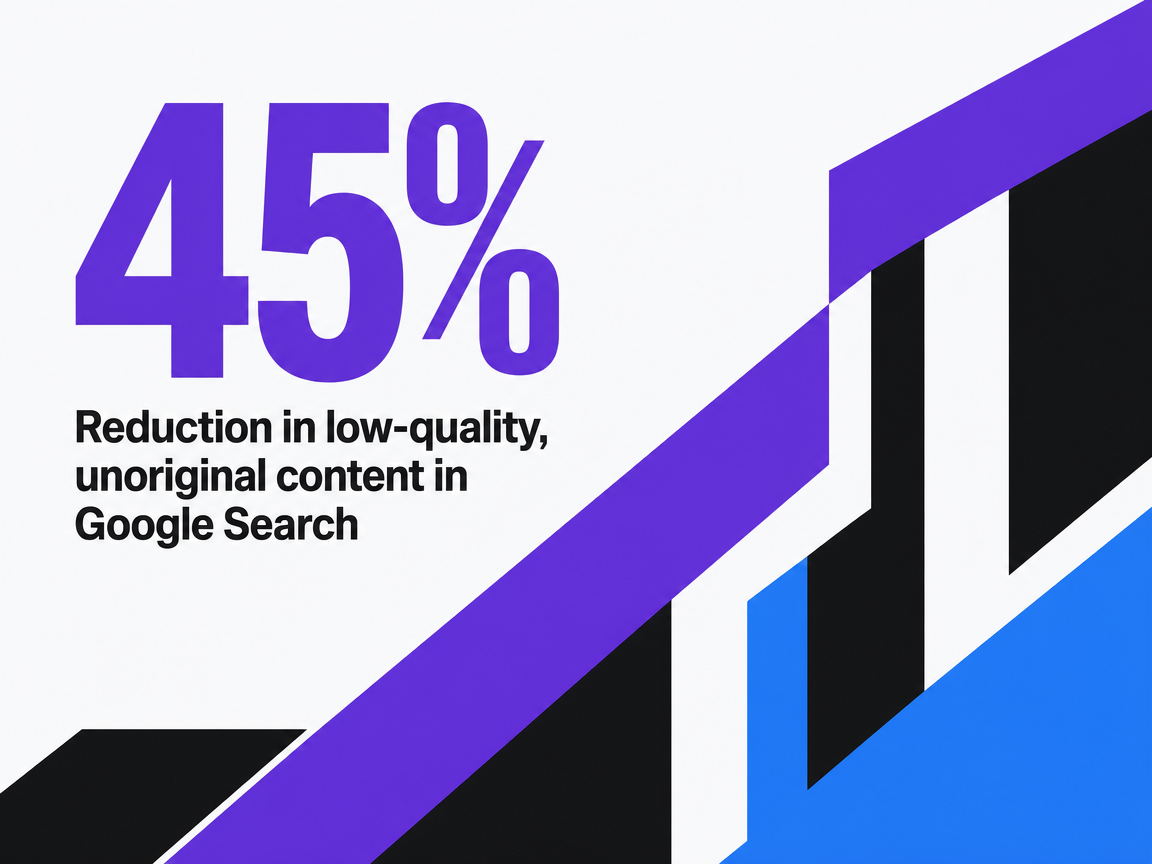 Reduction in low-quality, unoriginal content in Google Search
Reduction in low-quality, unoriginal content in Google Search
Reduction in low-quality, unoriginal content in Google Search
Test Autonomous SEO Execution In Real Time
Experience measurable SEO performance shifts by publishing live content and campaigns during your trial period.
Retainer cycles versus continuous execution: the economics directors actually compare
The choice growth directors are actually making in 2025 is not in-house versus agency. It is retainer-cycle execution versus continuous execution. The two models price similarly on paper and produce materially different assets in practice, and the gap shows up in the same line items every time: cycle latency, coordination overhead, and durability against ranking and search-surface change.
A traditional SEO retainer typically lands in a $3,000 to $15,000 monthly band depending on scope, with deliverables packaged into monthly sprints, standing planning calls, and quarterly business reviews. The cost of the work is not just the invoice. It is also the in-house calendar time absorbed by status meetings, brief reviews, vendor reconciliation across channels, and the latency between a Search Console signal and a live page revision — frequently three to six weeks under monthly cadence. Continuous-execution models, whether built in-house or delivered through an AI production layer, price against the same monthly band but compress those cycles into days because prioritization, approval, and production sit inside one operating layer rather than three. The Similarweb 2025 benchmarking work frames current measurement around integrated performance views rather than channel-isolated KPIs for exactly this reason 9.
| Variable | Retainer cycle | Continuous execution |
|---|---|---|
| Monthly cost band | $3,000–$15,000 typical agency range | Comparable band; cost shifts from coordination to production |
| Deliverable cadence | Monthly sprints, quarterly reviews | Daily prioritization, rolling publication |
| Director coordination overhead | 5–10+ hours per week reconciling vendors | Single account-level view; hours redirected to strategy |
| AI-search durability | Reactive to core updates and AI Overview shifts | Diagnostic protocols run within days of signal |
The 45% of B2B marketers expecting content budgets to increase and the 42% expecting them to stay flat 6are spending against the same search surface. The ones landing in the improving performance band are not the ones with bigger retainers. They are the ones whose operating model lets the budget reach live, instrumented work before the signal that prompted it goes stale.
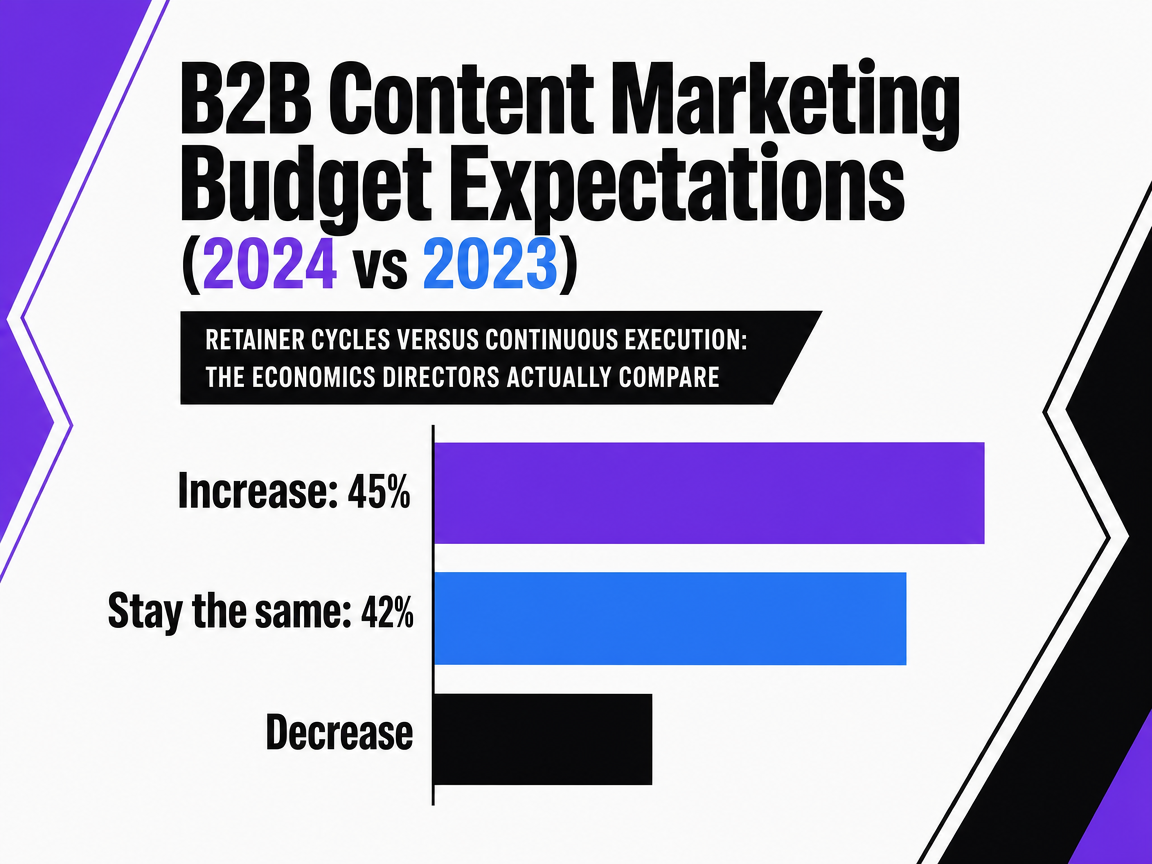 B2B Content Marketing Budget Expectations (2024 vs 2023)
B2B Content Marketing Budget Expectations (2024 vs 2023)
Breakdown of B2B marketers' expectations for their content marketing budgets in 2024 compared to the previous year. The remainder expected a decrease.
Evaluate Autonomous SEO Packages Built to Outperform Traditional Agencies
See how agency-quality SEO execution—powered by AI-driven coordination and specialist workflows—delivers measurable gains in efficiency, cost, and ranking performance for multi-site teams.
A 30-minute diagnostic to run against a current vendor or in-house program
The five criteria become operational when a director runs them against a real program in a single sitting. The diagnostic below takes about 30 minutes and produces a defensible decision artifact — keep, restructure, or replace — without scheduling a vendor call.
- Minutes 0–5: Pull the originality reject rate. Ask the program — vendor or in-house lead — for the last 90 days of drafts and the count of pieces killed or sent back for substantive rework before publication. A reject rate near zero indicates no quality bar is being enforced against Google's stated originality criteria 1. A documented 15–30% rework rate suggests the program is operating against a real standard.
- Minutes 5–10: Request the last core update response. Identify the most recent completed core update and ask what the program did within two weeks of it. The expected artifact is a segmented impact analysis by query and URL with a prioritization list — defend, consolidate, remove — consistent with Google's own diagnostic guidance 2. A general reassurance email is a fail.
- Minutes 10–18: Audit the conversion layer. Pull a sample of 10 organic landing pages produced in the last quarter. Count how many have a defined primary conversion event tied to pipeline and a secondary owned-audience capture mechanism. Anything below 70% indicates the program is still treating SEO as a traffic deliverable rather than a converted-action deliverable, which is no longer defensible against AI-mediated click compression 4.
- Minutes 18–24: Map coordination overhead. Sum the hours the director and team spend each week reconciling SEO, PPC, content, and link-building reporting across vendors or internal silos. Five-plus hours indicates a coordination tax that no single channel retainer is pricing in, but the in-house calendar is absorbing 9.
- Minutes 24–30: Score cycle time. Ask for median days from topic identification to publication and from underperformance signal to revision. If either median exceeds 21 days, the program is shipping work calibrated to a ranking environment three to four weeks behind the current one — which separates the 34% flat cohort from the 39% improving cohort in current B2B content research 7.
A program that fails on three or more of these dimensions is not a candidate for incremental improvement. It is a candidate for replacement with a continuous-execution model where prioritization, production, and approval sit inside one operating layer. Vectoron is one option in that category; the diagnostic itself is vendor-neutral and worth running against any program a growth director is currently funding.
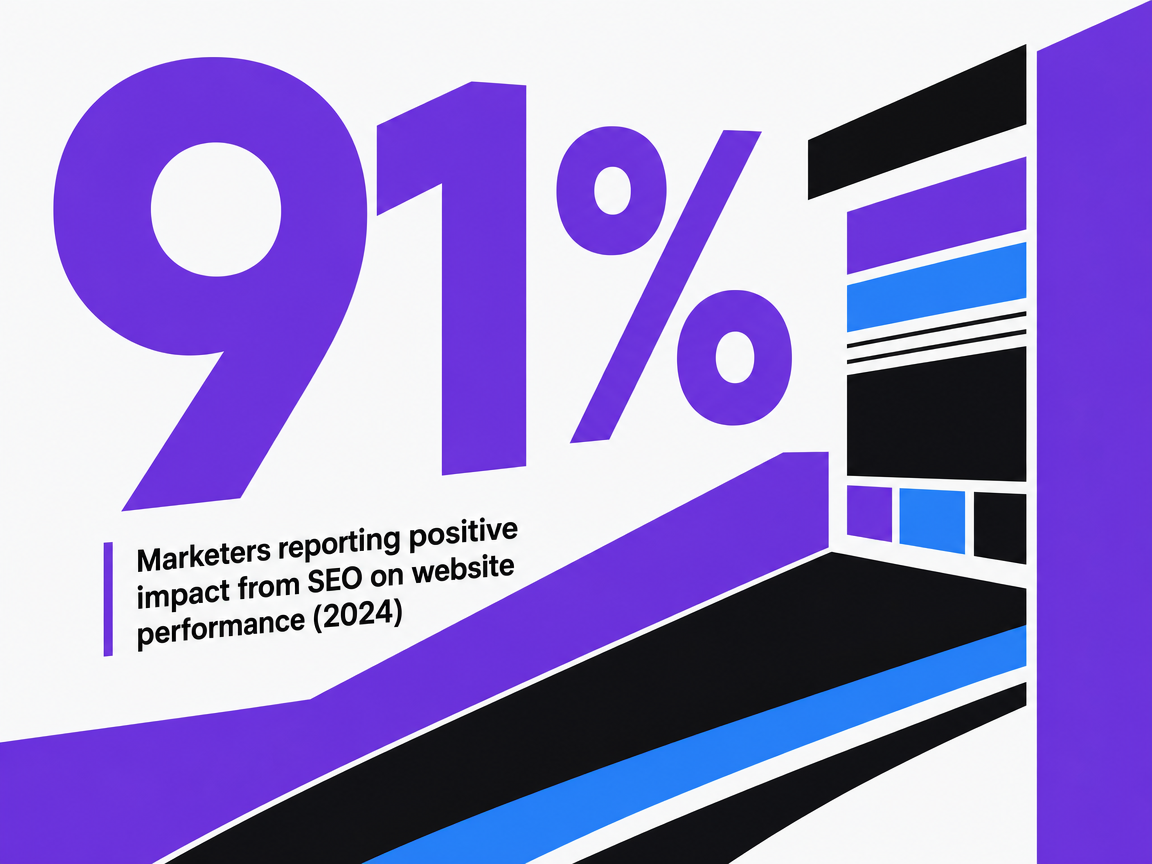 Marketers reporting positive impact from SEO on website performance (2024)
Marketers reporting positive impact from SEO on website performance (2024)
Marketers reporting positive impact from SEO on website performance (2024)
Frequently Asked Questions
References
- 1.Creating Helpful, Reliable, People-First Content | Documentation.
- 2.Google Search's Core Updates | Documentation.
- 3.New ways we're tackling spammy, low-quality content on Search.
- 4.Google's AI Overviews are hurting clicks: Pew study.
- 5.[Research Report] The State of SEO in 2025 - Conductor.
- 6.B2B Content Marketing Benchmarks, Budgets, and Trends.
- 7.B2B Content and Marketing Trends: Insights for 2026.
- 8.Marketing Benchmark Report - Similarweb.
- 9.2025 SEO Benchmarking Report - Similarweb.
- 10.Google Algorithm Updates & Changes: A Complete History.
- 11.Google's Helpful Content Update & Ranking System - What Happened and What Changed in 2024?.
- 12.Pew Research Confirms Google AI Overviews Is Eroding Web Ecosystem.