
Key Takeaways
- Profound delivers enterprise-grade monitoring across eight engines using live UI sampling, making it the defensible pick when client reporting must capture real retrieval-augmented generation behavior and citations 3.
- Peec AI fits mid-market retainers that need fast, actionable visibility insights without the workflow depth or cost profile of an enterprise suite, trading engine breadth for setup speed 5.
- Ahrefs Brand Radar earns a slot as research infrastructure, with a 190M+ prompt database that maps the prompt landscape during discovery and pairs naturally with a live monitor 6.
- The Semrush AI Visibility Toolkit bundles AI reporting into an existing SEO stack, setting competent floor coverage across a book where operational fit matters more than multi-engine depth 2.
- An execution layer is the fifth tool agencies skip at their own expense, routing ranked findings into approval-gated briefs so visibility scores move from shipped work rather than model drift 10.
The measurement-versus-execution split agencies keep getting wrong
The LLM visibility category has quietly bifurcated, and most agency tool stacks have not caught up. On one side sit measurement platforms that sample prompts across ChatGPT, Perplexity, Google AI Overviews, Copilot, Gemini, Grok, Meta AI, and DeepSeek to quantify how often a client surfaces in generated answers, what sentiment those mentions carry, and which sources the models cite 3. On the other side sit execution layers that route those findings into briefs, technical fixes, and approval queues so the work actually ships 10.
Agencies that buy only the measurement half end up with dashboards no one acts on. The visibility score moves, the share-of-voice chart updates, and the content team keeps shipping the same calendar it would have shipped without the tool. Agencies that skip measurement and double down on production optimize blind, with no way to prove a content investment changed how Perplexity or Google AI Overviews describes a client.
This split matters because the workflow these tools assume already exists in mature programs:
- Define the prompts that matter.
- Sample them at scale.
- Capture responses as structured data.
- Identify gaps.
- Feed recommendations back into content 1.
The handoff between step four and step five is where margin lives or dies on a multi-client book. The five tools that follow are sorted with that handoff in mind, not by feature count, and the buying matrix in the next section makes the tradeoffs explicit before any product names appear.
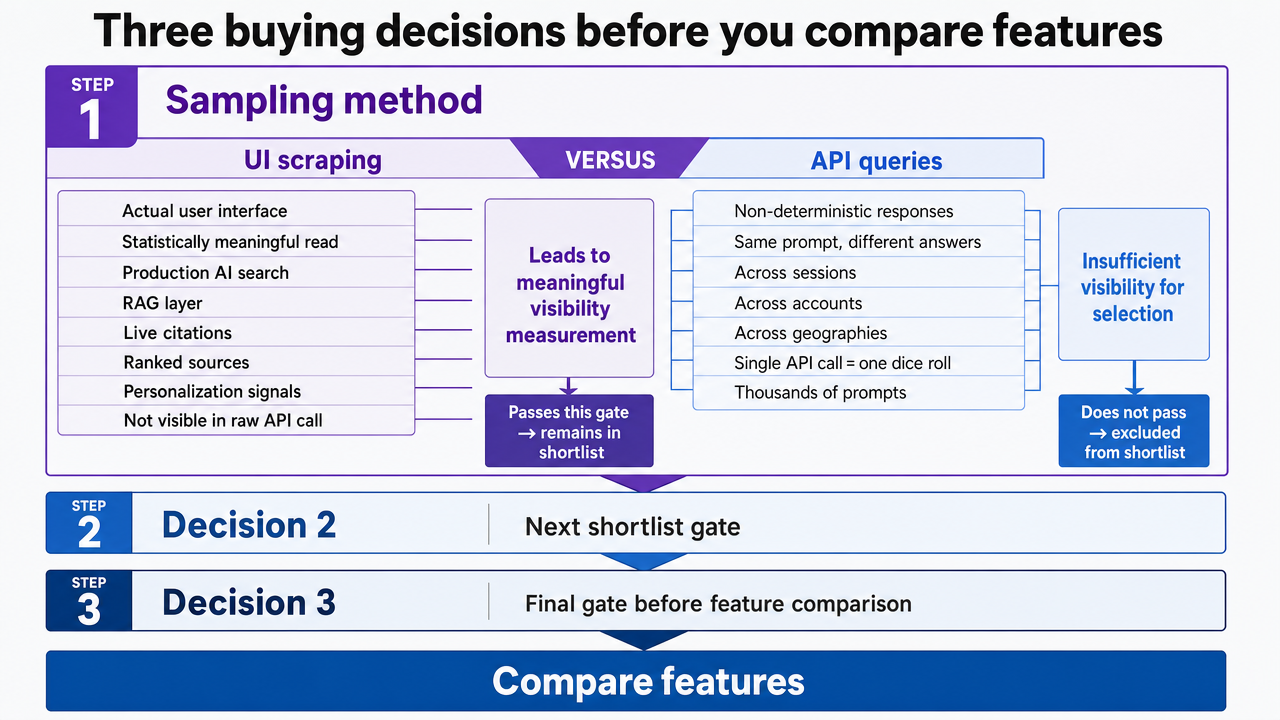
Three buying decisions before you compare features
Sampling method: UI scraping versus API queries
The first cut is technical, and it kills most shortlists fast. LLM responses are non-deterministic, which means the same prompt produces different answers across sessions, accounts, and geographies. A tool that pings an API once per prompt and reports a clean number is reporting a single dice roll. Backlinko's criterion is blunt: thousands of prompts run from the actual user interface, not just APIs, are required to get a statistically meaningful read on visibility 2.
The gap between UI sampling and API querying is not academic. Production AI search products run retrieval-augmented generation on top of base models, pulling in live citations, ranked sources, and personalization signals that never appear in a raw API call. Profound's review notes this directly: the platform monitors the actual AI search engines consumers use rather than querying static LLM APIs, which is what lets it capture real-time RAG-based answers and the citations driving them 3.
For an agency reporting to clients monthly, the practical filter is simple. Ask the vendor how many prompts per client per engine per month the platform runs, and whether those runs come from logged-in UI sessions or backend API calls. Tools that cannot answer with a specific four- or five-figure number per engine, or that admit to API-only sampling, will produce visibility scores that move because of model variance rather than because of any work the agency shipped. That is unreportable.
Engine coverage breadth
The second decision is which engines the tool actually watches. ChatGPT-only monitoring is no longer defensible for an agency book that includes B2B SaaS clients leaning on Perplexity, consumer brands surfacing in Google AI Overviews, and enterprise buyers querying Copilot inside Microsoft 365. Profound covers eight engines: ChatGPT, Perplexity, Google AI Overviews, Copilot, Gemini, Grok, Meta AI, and DeepSeek 3. Most competitors cover three to five, and the cheaper checkers often stop at two.
Coverage breadth matters for two reasons that show up in client conversations:
- First, share-of-voice math distorts when an engine is missing. A client that dominates ChatGPT but disappears in Perplexity and AI Overviews looks healthy on a narrow tool and exposed on a broad one.
- Second, the citation graph differs across engines. Perplexity links sources prominently, AI Overviews surfaces a different set of publishers, and Copilot pulls heavily from Bing's index. A monitor that only sees ChatGPT cannot tell an agency where to direct earned-media or digital-PR effort.
The buying rule is to match engine coverage to the client's actual buyer journey rather than to the tool's marketing copy. A legal-services client whose prospects research on Google needs AI Overviews coverage. A developer-tools client needs Perplexity and ChatGPT. Paying for eight engines makes sense only when the book spans enough buyer behaviors to use them.
Execution handoff: what happens after the dashboard
The third decision is the one most evaluations skip. A visibility tool produces a list of gaps: prompts where the client is absent, competitors who are cited instead, content topics the model associates with the wrong brand, and citation sources worth pursuing. None of that ships content. The agency still has to translate findings into briefs, route them through editorial review, get client approval, produce the work, publish it, and rerun the prompts to confirm the score moved.
That handoff is where retainer margin disappears. A junior analyst pulling a weekly export from Profound or Peec AI, summarizing it into a Google Doc, and emailing it to a content lead is a labor pattern that scales linearly with client count. Ten clients means ten analysts' worth of summarization work, regardless of how good the dashboard is. The category framing that matters here is explicit: visibility signals need to route into content briefs and approval workflows so agencies can act on tracker data at scale 10.
The buying question is whether the measurement tool exports cleanly into whatever production system the agency already runs, or whether a separate execution layer needs to sit between the tracker and the content team. Either answer is defensible. Choosing neither, and assuming analysts will absorb the gap, is not.
 Visualize the three-decision buying framework that gates tool selection before feature comparison, directly mirroring the section's three subsections
Visualize the three-decision buying framework that gates tool selection before feature comparison, directly mirroring the section's three subsections
Test AI-driven visibility at full operational scale
Run live LLM optimization campaigns and measure impact across multiple client sites during your trial period.
The measurement layer: four tools worth shortlisting
Profound: enterprise depth across eight engines
Profound is the most defensible pick when the client book includes enterprise accounts that need defensible reporting across the full AI search surface. The platform tracks brand visibility and share of voice across eight engines: ChatGPT, Perplexity, Google AI Overviews, Copilot, Gemini, Grok, Meta AI, and DeepSeek 3. That coverage is currently unmatched among general-purpose monitors, and it forces every shortlist to start with the question of whether a narrower tool can credibly report on the same buyer journey.
The architectural choice driving that coverage matters more than the engine count itself. Profound samples the actual consumer interfaces rather than querying static LLM APIs, which means the responses it captures include the live retrieval-augmented generation behavior, citations, and ranked sources that users actually see 3. For an agency, this is the difference between reporting on what a model could say in isolation and reporting on what the model is saying right now to a logged-in user running a real query.
The feature set practitioners flag as agency-relevant is consistent across reviews: visibility scores, citation analysis, sentiment tracking, and competitive positioning, plus the ability to identify which sources the models cite so outreach and digital-PR effort can be aimed at the right publishers 4. The honest limitation is price-to-value at the smaller end of a book. Profound targets enterprises with comprehensive monitoring and workflow integration, and the cost reflects it 5. Agencies running mostly SMB retainers will struggle to amortize an enterprise-tier license across clients whose budgets cannot absorb a proportional share. The tool earns its place when at least a few accounts in the portfolio need eight-engine reporting and the agency can centralize licensing rather than billing it through per-client.
Peec AI: mid-market speed over enterprise depth
Peec AI is the answer to the question Profound's pricing raises. The platform serves mid-market teams that need fast, actionable insights without the workflow integration depth or cost profile of an enterprise suite 5. For an agency book weighted toward growth-stage SaaS, professional services, or regional multi-location brands, that tradeoff lands in the right place.
The category framing in the head-to-head with Profound is explicit: both tools deliver LLM brand visibility insights, and the choice comes down to company size, complexity, and budget 5. Peec AI's positioning leans into faster setup, a tighter feature surface, and reporting that a content lead can read without a dedicated analyst translating it. That speed is the operational advantage. An agency onboarding a new client in week one wants a visibility baseline by week two, not a six-week implementation.
The honest limitation is coverage and depth. Peec AI does not match Profound's eight-engine breadth or the same level of citation-source analysis, which means an enterprise client expecting reporting across every consumer AI surface will find gaps. For mid-market accounts where the buyer journey concentrates in two or three engines, that gap is not a problem. For an account where the CMO wants to see Copilot, Meta AI, and DeepSeek alongside the obvious surfaces, it is.
The portfolio play is using Peec AI as the default monitor for the bulk of a mid-market book and reserving a heavier tool for the handful of accounts that demand enterprise breadth. That two-tool stack tends to pencil out better than forcing a single platform across mismatched client sizes.
Ahrefs Brand Radar: SEO-adjacent prompt research at scale
Ahrefs Brand Radar approaches the category from the SEO-analytics side rather than from a purpose-built monitor. The product is built around a 190M+ prompt database, integrated SEO and AI analytics, AI traffic tracking, and competitive gap analysis, aimed at enterprise brands and large research operations 6. For an agency already standardized on Ahrefs for keyword research, backlinks, and site audits, that integration is the structural argument.
The prompt database is the headline asset. A monitor that runs live prompts is reporting on what the model says today. A research database of that scale is reporting on the prompt space itself: what people are actually asking, how those prompts cluster, and which entities appear in responses across the corpus. Those are different questions, and they serve different stages of an engagement. Brand Radar is stronger for the discovery phase, when an agency is mapping a client's prompt landscape and identifying which queries to monitor going forward.
The limitation is that integrated SEO-plus-AI analytics is not the same as deep, multi-engine front-end sampling. The 190M+ prompt database is research infrastructure, not a substitute for the live UI-sampling approach that defines tools like Profound 3. For an agency that needs both a research backbone and ongoing visibility tracking, Brand Radar pairs naturally with a dedicated monitor rather than replacing one.
The fit is cleanest for agencies whose clients already pay for Ahrefs through the SEO line item. Adding Brand Radar as an extension of an existing license is far easier to justify than introducing a separate vendor relationship, and the cross-tool workflows reduce the friction of moving from keyword research to prompt research.
Semrush AI Visibility Toolkit: bundling visibility into an existing stack
The Semrush AI Visibility Toolkit follows the same logic as Brand Radar from a different starting point. It is positioned as a dedicated analytics layer added to a platform agencies already use for traditional SEO, positioning AI visibility as an extension of existing reporting rather than a separate procurement 2, 6.
The argument for bundling is operational, not technical. An agency Head of SEO running Semrush across a portfolio already has client accounts provisioned, reporting templates built, and team training in place. Adding an AI visibility module routes the new data into the same dashboards account managers open every Monday. The friction of introducing a standalone tool, with separate logins, separate data exports, and separate client invoices, is real and recurring.
The limitation is the same one that applies to every bundled module in a broad SEO suite. Depth of multi-engine coverage, sampling rigor, and citation analysis are unlikely to match what a purpose-built monitor delivers. For agencies whose clients need a competent visibility read alongside their existing SEO reporting, the toolkit clears the bar. For accounts where AI visibility is the headline service line and the primary reporting deliverable, a dedicated monitor remains the stronger pick. The realistic play is using the bundled toolkit as the floor across the book and upgrading specific accounts to a specialized tool when the engagement justifies it.
The execution layer: turning visibility signals into shipped work
A measurement tool produces a queue:
- Prompts where the client is missing.
- Prompts where a competitor owns the answer.
- Citation sources the model trusts that the client has never been mentioned in.
- Sentiment dips on specific topics.
That queue is the deliverable from the dashboard. What the dashboard does not do is write the brief, get it approved, produce the asset, publish it on the right URL with the right schema, and rerun the prompts six weeks later to confirm the visibility score moved.
The category framing for that gap is direct: visibility signals need to route into content briefs and approval workflows so agencies can act on tracker data at scale 10. Without that routing, a senior strategist becomes a translator. A weekly export from Profound or Peec AI gets read, summarized into a Google Doc, emailed to a content lead, debated in a Slack thread, and then half-implemented two sprints later because production capacity was already booked against last quarter's editorial calendar. The signal decays before it ships.
The execution layer is whatever sits between the tracker and the published asset. For some agencies that is a project management stack plus a content ops lead. For others it is an AI marketing team platform that turns ranked findings into approval-gated briefs, routes them through editorial review, executes the approved work across content and technical SEO, and writes the outcome back to the tracker so the next sampling run measures lift rather than drift. The infrastructure trend points the same direction: prompt optimization itself is being formalized at the platform layer, with services like Vertex AI Prompt Optimizer automating what used to be manual tuning work 9.
The honest test for any execution layer is whether the agency's per-client analyst hours go down as client count goes up. If they scale linearly, the dashboard is winning and the agency is losing margin. If they flatten, the handoff is real.
Scale LLM Visibility Across Clients Without Increasing Headcount
See how leading agencies leverage AI-powered platforms to automate LLM visibility optimization, maintain quality control, and accelerate SEO delivery—supported by workflow oversight and measurable impact at scale.
Portfolio economics: how the math changes across a client book
Tool selection stops being a feature exercise once an agency runs the same decision across twenty or thirty retainers. The question becomes whether a license sits on a single client P&L or absorbs into the agency's overhead, and the answer shifts the unit economics of the whole service line. A per-client add-on works when the retainer carries enough margin to bury a four-figure tool fee without renegotiation. An agency-wide license works when the same platform spans enough accounts that the per-client allocation drops below what any single client would pay standalone.
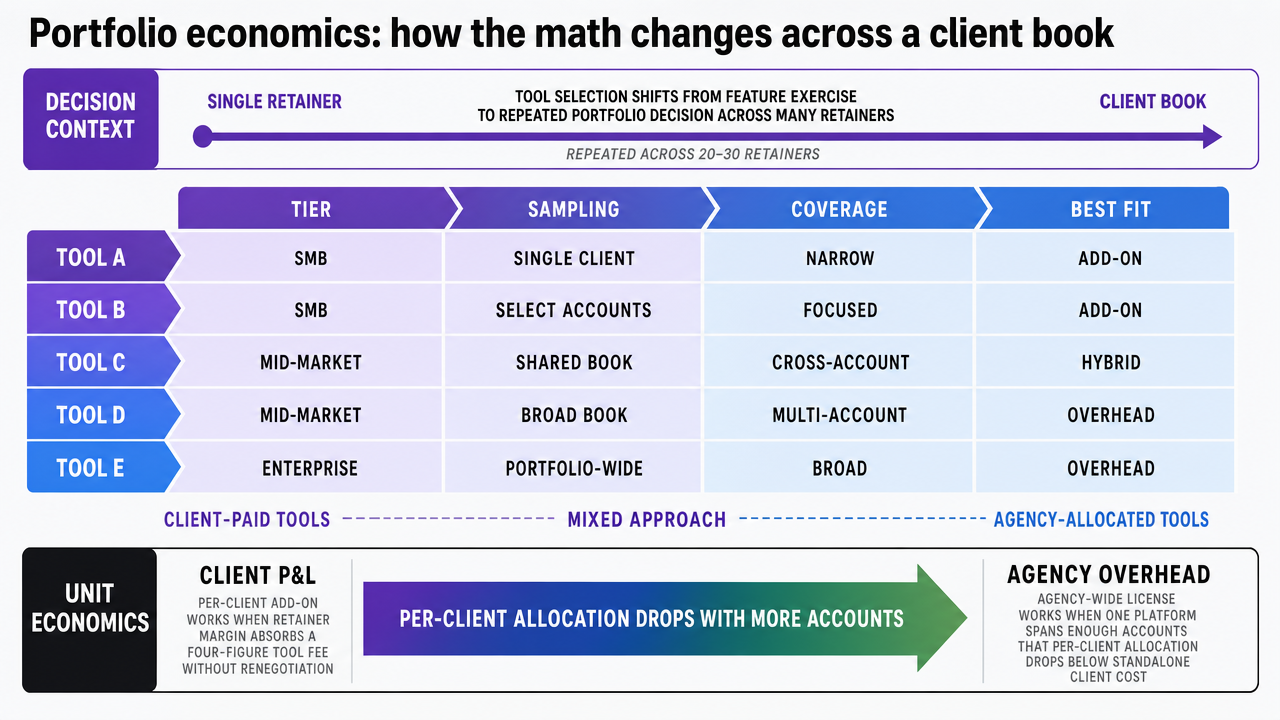
The roundup landscape supports both models. Vendor positioning ranges from SMB-friendly tools to enterprise suites, with mid-market options sitting between, and pricing tiers reflect the same spread 6. Mapped against an agency book, the practical layout looks like this:
| Tool | Tier | Sampling | Engine coverage | Typical agency fit |
|---|---|---|---|---|
| Profound | Enterprise | UI front-end | 8 engines 3 | Centralized license, allocated to enterprise accounts |
| Peec AI | Mid-market | UI-based | Narrower set | Per-client or pooled across mid-market retainers 5 |
| Ahrefs Brand Radar | Enterprise research | Prompt database (190M+) | Multi-engine research 6 | Add-on to existing Ahrefs agency license |
| Semrush AI Visibility Toolkit | SMB to mid-market | Bundled module | Multi-engine, bundled | Floor coverage across the full book |
| SMB checkers (Cairrot class) | SMB | Varies, often API | 2–3 engines 6 | Per-client only when budget caps depth |
Pricing should be confirmed direct with vendors; the segmentation above reflects positioning, not quoted figures. The retainer math that matters runs in the other direction. If a tool replaces eight hours of monthly manual prompt auditing across ten clients, the agency recovers eighty analyst hours a month. At a loaded analyst rate, that ceiling is what the tool has to clear before the spend stops being additive. The recovery only lands when findings actually ship, which is why a measurement license without an execution layer tends to underperform its own business case. The dashboard runs, the analyst hours stay billed, and the score moves by drift rather than by work.
 Visualize the five-tool portfolio comparison table that already exists in the section, making the tier/sampling/coverage/fit mapping scannable
Visualize the five-tool portfolio comparison table that already exists in the section, making the tier/sampling/coverage/fit mapping scannable
A shortlist verdict for 2026
The five-tool shortlist sorts cleanly once the measurement-versus-execution split drives the decision.
- Profound is the enterprise-grade monitor when the book demands eight-engine coverage and front-end sampling that captures live retrieval behavior 3.
- Peec AI is the mid-market default for agencies whose retainers cannot absorb enterprise pricing but still need fast, actionable insights 5.
- Ahrefs Brand Radar earns its slot as research infrastructure for agencies already standardized on the platform, with a 190M+ prompt database that complements rather than replaces live monitoring 6.
- The Semrush AI Visibility Toolkit sets the floor across a broad book where bundling matters more than depth 2, 6.
The fifth slot belongs to the execution layer, and skipping it is the most expensive mistake in the category. A measurement license without a workflow that routes findings into briefs, approvals, and published assets produces dashboards that decay between sampling runs 10. Vectoron sits in that slot for agencies operationalizing AI visibility across a portfolio, turning ranked findings into approval-gated work so the score moves because the agency shipped, not because the model drifted. The verdict: pair one measurement tool to the book's center of gravity, and put an execution layer behind it before the first quarterly report lands.
Frequently Asked Questions
References
- 1.Best Tools for LLM Visibility and AI Brand Monitoring in 2026.
- 2.5 AI Visibility Tools to Track Your Brand Across LLMs.
- 3.My Profound AI Search Visibility Review (for SaaS / Tech B2B).
- 4.Jay's AI SEO Tips on Profound LLM Visibility Tool Review [Video Spotlight].
- 5.Peec AI vs. Profound: Choosing the Right LLM Brand Visibility Tool.
- 6.Best LLM Visibility Software: 11 Tools for AI Search (2026).
- 7.AI Search Optimization: Understanding Prompt-Based Discovery.
- 8.RAG Optimization Tools are the Key to GenAI Accuracy.
- 9.Announcing Vertex AI Prompt Optimizer.
- 10.Best LLM SEO Tracking Tool Options for Agencies and AI Visibility.