
Key Takeaways
- Evaluate SEO automation platforms as marketing infrastructure rather than feature checklists, since capability matrices reward breadth while ignoring outcome alignment, operating model fit, and governance depth 12.
- Four traits separate infrastructure from another tool: live business outcome data as input, governed approval workflows, vertical and revenue-model tailoring, and auditable reasoning behind every recommendation.
- Technical monitoring and Core Web Vitals tracking are baseline expectations, while AI-surface visibility across Overviews and assistants is now a current criterion, not a roadmap item 8.
- Multi-location operators should audit their fragmented stack against total cost of execution, since consolidation only pays off when the unified platform produces work teams approve rather than rewrite 9.
The Evaluation Question Has Shifted
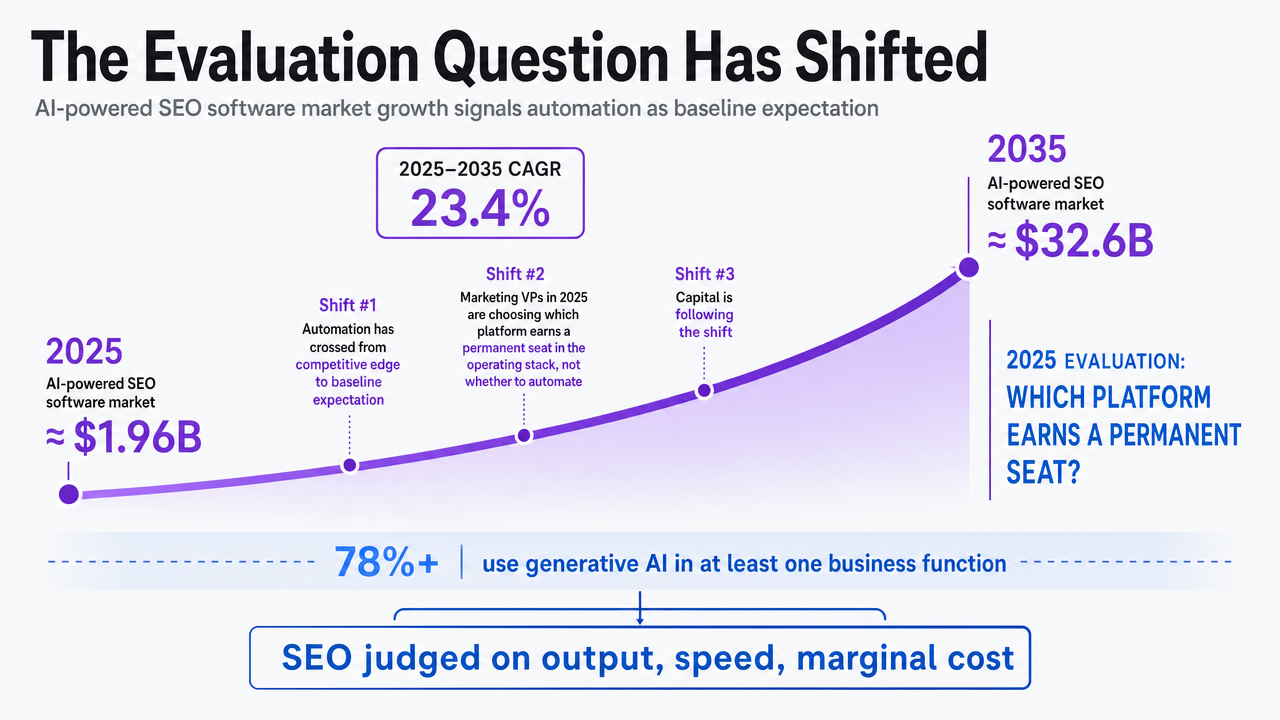
Marketing VPs evaluating SEO automation in 2025 are not deciding whether to automate. They are deciding which platform earns a permanent seat in their operating stack. The global AI-powered SEO software market sat at roughly $1.96B in 2025 and is projected to reach $32.6B by 2035, a 23.4% compound annual growth rate 2. That trajectory reflects something more interesting than vendor enthusiasm: automation has crossed from competitive edge to baseline expectation, and capital is following the shift.
The organizational context has moved with it. More than 78% of organizations now use generative AI in at least one business function 4, which means the executives sitting around the budget table have working assumptions about what AI should produce, how fast, and at what marginal cost. SEO is being evaluated against those assumptions, not against the prior generation of rank-tracking dashboards and crawl reports.
Forrester's analysts have argued for some time that SEO platforms now function as core marketing infrastructure rather than niche specialist tools 5. That reframe matters for how a VP scopes the decision. Infrastructure choices are evaluated on data depth, cross-channel reach, integration with analytics, and the ability to coordinate work across teams—not on which vendor ships the prettiest keyword explorer.
The practical question for a VP overseeing organic pipeline is no longer "does this tool automate SEO tasks." It is "does this platform replace a coordination layer my team currently buys from agencies and stitches together from point tools, and does it do so without surrendering oversight." The rest of this guide works through the criteria that distinguish infrastructure from another tool to manage.
 Visualize the projected growth of the AI-powered SEO software market cited in this section to reinforce why automation has crossed from competitive edge to baseline expectation
Visualize the projected growth of the AI-powered SEO software market cited in this section to reinforce why automation has crossed from competitive edge to baseline expectation
Why Feature-Checklist Scoring Misleads VPs
The standard procurement reflex is to build a capability matrix, weight the columns, and let the highest score win. That approach produces defensible memos and the wrong platform. Outcome alignment frequently diverges from capability density: a VP can score every vendor in an analyst rubric against the same criteria and still buy a tool that fails to move pipeline because the rubric measured features instead of business results 12.
The gap shows up in three predictable ways.
- Checklists reward breadth. A platform that ships every adjacent feature scores higher than one that executes fewer functions exceptionally well, even when the second platform produces better organic outcomes for the specific revenue model.
- Checklists are silent on the operating model. They record whether a feature exists, not whether the team will adopt it, whether it integrates with the systems already running the business, or whether the AI components produce work a marketing director will approve without rewriting. IBM's enterprise survey flagged limited AI skills, data complexity, and integration friction as the dominant barriers to AI adoption 3—none of which appear on a feature scorecard.
- Checklists treat governance as a binary. Approval workflows, audit trails, and reasoning transparency get a single checkbox, when in practice these capabilities span a wide spectrum that determines whether a platform earns long-term trust from legal, brand, and executive stakeholders.
A more useful evaluation question replaces "what does it do" with "what does it produce, against what inputs, under whose approval, and how is the work measured against pipeline." The next four traits operationalize that question.
Four Traits That Separate Infrastructure From Tools
Live Business Outcome Data, Not Just Rankings
Rankings and organic sessions are lagging proxies for what a VP actually owns: qualified pipeline. A platform that optimizes against keyword positions without ingesting downstream conversion data is solving a different problem than the one on the operating plan. The criterion worth pressing during evaluation is whether the system can read live business signals—booked appointments, qualified calls, cost per lead, won revenue by service line—and use those signals to rank what to work on next.
This matters because the work a content team prioritizes changes when the input data changes. Optimizing the page that ranks #6 for a high-volume keyword is the obvious move from a rank-tracker view. Optimizing the page that ranks #6 for a keyword tied to the highest-margin service line, where call quality is already strong but session-to-call conversion lags, is the obvious move from an outcome view. Only the second decision compounds into pipeline.
The practical evaluation test is granular. Does the platform accept call tracking data, CRM stage transitions, and revenue attribution as first-class inputs, or does it treat them as exported reports stapled onto the side of a rank dashboard? Can it weight recommendations by service-line economics rather than by traffic potential alone? When a content brief is generated, does the underlying model see which prior briefs produced conversions, not just impressions?
Forrester's case for SEO platforms as core marketing infrastructure rests on centralized visibility and cross-channel insight 5. That visibility is only useful if the data feeding it includes the metrics a VP defends in board reviews. Platforms that stop at rankings hand the outcome conversation back to the agency.
Governed AI Execution With Explicit Approval Workflows
Governance is where most automation platforms reveal whether they were designed for marketing operators or for solo practitioners. The capability matrix shows a checkbox next to "approval workflows." The operating reality is a spectrum, and the position on that spectrum determines whether legal, brand, and the executive team will tolerate the platform six months in.
Three governance questions sort the field quickly.
- What work can the platform execute autonomously, and what work requires a human signature before it ships? A platform that publishes content, edits metadata, or pushes schema changes without review is a liability in regulated verticals where a misstated claim triggers compliance review. A platform that routes every material change through a named approver, with the AI's reasoning attached, behaves like infrastructure a marketing director can defend.
- Who approves what, and can roles be scoped? A content editor approving title-tag changes is different from a legal reviewer approving a behavioral-health landing page. The platform should support role-based queues, not a single "approve all" button. IBM's enterprise survey flagged limited AI skills and integration friction as primary AI adoption barriers 3, and both pressures get worse when governance is undifferentiated.
- What does the audit trail capture? Approval-first systems should log the recommendation, the input signals it drew from, the approver, the timestamp, and the result. That record turns the AI from a black box into a reviewable colleague.
The spectrum runs from full autonomy with no review, to suggestion-only tools that produce nothing without manual rework. The productive middle is approval-first automation: the AI proposes, ranks, and prepares finished work; the human approves; the system executes and tracks the result. Platforms that occupy that middle scale execution without surrendering oversight.
Vertical and Revenue-Model Tailoring
Generic platforms produce generic recommendations. A national keyword research feature does not know that a behavioral-health intake coordinator measures qualified call rate, that a multi-location dental group cares about new-patient appointments by location, or that a personal injury firm tracks signed cases per practice area. Recommendations that ignore those distinctions get ignored by the operators receiving them.
Enterprise AI buyers have already revealed how they weight this. In Menlo Ventures' 2024 enterprise survey, 30% of buyers cited measurable value as their top priority when selecting AI applications and 26% cited contextual understanding of their business, while only 1% cited price as the primary concern 11. Vertical fit is not a soft preference. It is the dominant decision criterion among buyers who have already lived through generic AI deployments that produced output their teams refused to use.
The evaluation test runs in two directions. On the input side: can the platform model the revenue structure of the business? Service-line margin differences, location-level demand variance, payor or insurance dynamics, seasonal intake patterns, and lead-quality thresholds all change which SEO work matters. On the output side: do the recommendations name the right competitors, the right schema types, the right local pack dynamics, and the right conversion bottlenecks for the vertical? A platform that recommends generic blog topics for a multi-location senior-living operator is producing content for a different business.
The price question matters far less than the relevance question. A cheaper platform that produces work the team has to rewrite is more expensive than the relevance gap suggests, because the hidden cost is the marketing director's time and the lost weeks of execution. Tailoring is the criterion that protects that time.
Auditable Reasoning Behind Every Recommendation
A recommendation without reasoning is an instruction the team has to either trust blindly or rebuild from scratch. Both options waste the platform's main advantage. Auditable reasoning means every ranked suggestion arrives with the inputs it considered, the logic that produced it, and the expected outcome it is optimizing for—visible to the approver before they sign off.
This is partly a trust question and partly an operational one. On trust: a marketing director who can read why the platform proposed restructuring a service-area page is far more likely to approve the change quickly than one staring at a recommendation labeled only "high priority." On operations: when a recommendation does not produce the expected lift, auditable reasoning makes the post-mortem possible. The team can see whether the input signal was wrong, the logic was flawed, or the execution diverged from the plan.
The practical test during evaluation is to ask the vendor to surface a recommendation and walk through the reasoning chain end to end. Which data sources fed it? What weight did each input carry? What outcome metric does the platform expect to move, and over what window? If the answer is a confident assertion without a traceable chain, the platform is asking for trust it has not earned. If the answer is a transparent record, the platform is behaving like infrastructure that compounds learning over time rather than producing one-off suggestions that disappear after execution.
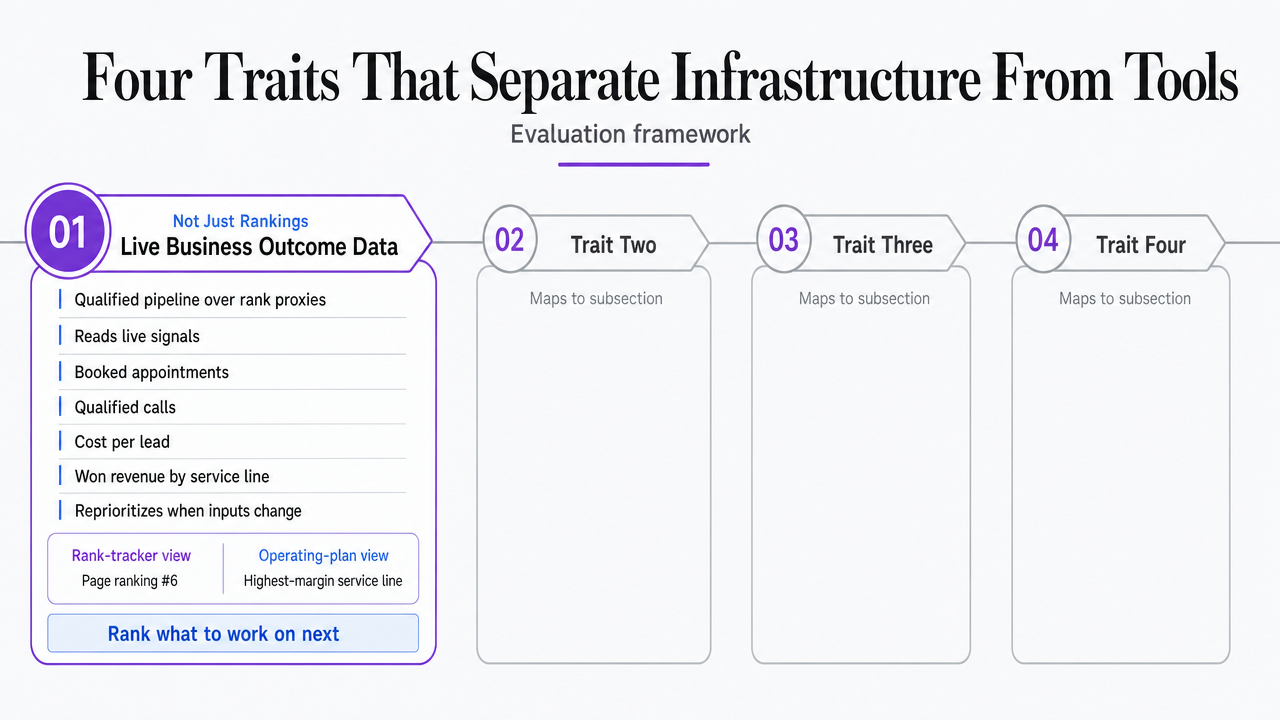 Process infographic summarizing the four evaluation traits introduced in this section, giving readers a scannable framework that maps directly to the subsections
Process infographic summarizing the four evaluation traits introduced in this section, giving readers a scannable framework that maps directly to the subsections
Experience Data-Driven SEO Automation in Action
Assess real-time impact by publishing live SEO content and measuring performance during your trial.
Technical Monitoring as a Baseline, Not a Differentiator
Crawlability, indexation, schema validity, and Core Web Vitals monitoring belong in the floor of any serious platform, not the ceiling. Google publishes specific thresholds for a good page experience: Largest Contentful Paint under 2.5 seconds, Interaction to Next Paint under 200 milliseconds, and Cumulative Layout Shift under 0.1 6. A platform that cannot continuously measure those metrics at the page-template level, alert on regressions, and tie the regression back to a specific deployment is missing table stakes.
The nuance worth carrying into the evaluation conversation is that Core Web Vitals influence rankings as part of holistic page experience scoring rather than as a standalone ranking system 7. Hitting the thresholds does not produce a ranking lift on its own, and missing them does not flatten a page that is otherwise dominant on relevance and authority. The implication for platform selection is direct: technical monitoring is necessary to defend the floor, but a platform that treats Core Web Vitals as its headline feature is selling commodity capability at a premium.
Where technical monitoring becomes a real differentiator is in the connection to execution. Detecting that LCP on the highest-converting service-line template degraded from 2.1 to 3.4 seconds after a CMS update is the easy part. The harder, more valuable behavior is routing that finding into a ranked queue, tying it to the revenue exposure on that template, drafting the fix, and surfacing it to the right approver with the engineering context attached. Platforms that stop at the dashboard hand the work back to the team. Platforms that close the loop into governed execution earn the seat in the stack.
Multi-Channel Execution as a Single Surface
SEO no longer operates as a standalone discipline. A service-line landing page that ranks depends on the technical template engineers ship, the schema the content team writes, the local citations the location operations team maintains, the inbound links the PR function earns, and the call-handling quality that converts the resulting traffic. A platform that treats SEO as an isolated workstream is automating one corner of a system the VP has to coordinate anyway.
The useful evaluation question is whether the platform exposes content, technical, links, local, and conversion analytics as a single execution surface—one queue, one approval model, one record of what shipped and what it produced. Forrester's framing of SEO platforms as core marketing infrastructure rests on that consolidation: centralized data, cross-channel insight, and collaboration across teams without per-channel handoffs 5. Fragmentation across separate tools recreates the agency coordination tax the platform was supposed to eliminate.
The operational test is what happens between a signal and a shipped change. If a ranking drop on a money page surfaces in one tool, the schema audit lives in a second, the link-building queue sits in a third, and the local listing update runs through a fourth, the VP is still buying coordination. A unified surface routes the signal, the recommended response across channels, and the approvals into one workflow with a shared outcome record.
AI-Surface Visibility as a Current Criterion
Search behavior is fragmenting across surfaces faster than most evaluation cycles account for. Sixty-six percent of consumers expect AI to replace traditional search engines within five years, and projections place 90 million Americans using AI for search by 2027 8. A platform evaluated only against blue-link SERPs is optimizing for a shrinking share of how prospects actually find service providers.
The criterion is not whether the platform mentions AI Overviews in its marketing copy. It is whether the system measures presence across AI surfaces—Overviews, assistants, summary panels—tracks which queries trigger which surface for the relevant vertical, and adjusts content structure to earn citation in those answers. Schema depth, entity clarity, and direct-answer formatting carry different weight when the goal is being cited by an assistant rather than ranked in a list.
The practical test during demos is direct. Ask the vendor to show AI-surface visibility for a competitor in the buyer's vertical, identify which content properties earn citations, and explain how the platform would close the gap. A vendor that treats AI search as a 2027 roadmap item is selling a platform built for the search environment of 2022.
Evaluate SEO Automation Platforms With Data-Backed Precision
Connect with our team to access a comparative analysis of leading SEO automation solutions, including workflow automation benchmarks, integration capabilities, and efficiency metrics tailored for agencies and enterprise-scale requirements.
Consolidation Economics for Multi-Location Operators
If You Manage Multiple Locations: The Stack Audit
The economics of platform selection change when a VP is responsible for ten, fifty, or three hundred locations rather than a single domain. This section narrows to that scenario. Multi-location operators in legal, behavioral health, dental, home services, senior living, and healthcare typically carry a stack that grew by accretion: a technical SEO crawler bought when the engineering team needed audit data, a content optimization tool layered on by the marketing director, a rank tracker held over from a prior agency, a link prospecting tool used by a freelancer, a local listings manager for the storefront network, a reporting tool stitched on top, and one or two agency retainers covering the gaps.
The audit worth running before any platform evaluation begins is a line-item inventory of that stack. List every tool, its annual cost, the number of seats actually used, the agency retainers paid against SEO scope, and the internal hours spent moving data between systems. The hidden line is the coordination tax: the time a marketing director spends reconciling rankings from one tool with conversions in a second and brief approvals in a third. Companies that have implemented marketing automation report roughly 14.5% higher sales productivity and 12.2% lower overhead 9. Those gains do not arrive from the software alone. They arrive from collapsing the coordination tax that fragmented stacks impose.
Comparing Fragmented Stacks Against a Unified Platform
The honest comparison is not platform price against tool price. It is total cost of execution against total cost of execution, where execution means signals captured, recommendations ranked, work approved, changes shipped, and outcomes measured across every location. The table below frames the categories a multi-location operator should populate with their own numbers rather than borrowed industry averages.
| Cost Category | Fragmented Stack | Unified Platform |
|---|---|---|
| Technical SEO tool | Annual license | Included |
| Content optimization tool | Annual license | Included |
| Rank tracking | Annual license | Included |
| Local listings manager | Per-location fee | Included or per-location |
| Link prospecting tool | Annual license | Included |
| Reporting and dashboards | Annual license + build time | Included |
| Agency retainers for SEO scope | Monthly retainer | Reduced or eliminated |
| Internal coordination hours | Marketing director time | Approval queue time |
| Briefing and handoff cycles | Per-deliverable | Eliminated |
The categories the reader fills in are the ones that matter. A platform that consolidates eight line items into one but produces work the team rewrites is not a savings—it is a relocation of the same overhead. The traits established earlier in this guide—live outcome data, governed approval workflows, vertical tailoring, and auditable reasoning—are what determine whether consolidation actually reduces the total cost of execution or simply renames it 12.
Operator Guidance for the Selection Process
Run the evaluation against the four traits in sequence, not in parallel.
- Live outcome data is the first gate—a platform that cannot ingest call tracking, CRM stage data, and revenue attribution as first-class inputs is solving for rankings while the VP is graded on pipeline.
- Governed approval workflows are the second gate, because a platform that ships unreviewed work in a regulated vertical creates more risk than the agency it replaced.
- Vertical tailoring is the third, and the dominant criterion for enterprise AI buyers who learned the hard way that generic output gets rewritten or ignored 11.
- Auditable reasoning is the fourth, and the one that determines whether the platform compounds learning or produces forgettable suggestions.
Structure the demo accordingly. Bring real data—a service line, a location set, a recent ranking drop on a money page—and ask the vendor to produce a ranked recommendation with the reasoning chain visible, route it through an approval queue, and show how the outcome would be measured. Vendors that cannot run that exercise on live inputs are selling a dashboard. For VPs ready to consolidate the stack on infrastructure rather than another tool to manage, Vectoron is built around that operating model.
 Projected CAGR of AI-powered SEO Software Market (to 2035)
Projected CAGR of AI-powered SEO Software Market (to 2035)
Projected CAGR of AI-powered SEO Software Market (to 2035)
Frequently Asked Questions
References
- 1.SEO Automation Tools 2026: The Complete Guide.
- 2.AI-powered SEO Software Market Size | CAGR of 23.4%.
- 3.Data Suggests Growth in Enterprise Adoption of AI is Due to Widespread Deployment by Early Adopters.
- 4.AI Adoption Statistics Q1 2026: All Figures.
- 5.Every Company Needs An SEO Platform.
- 6.Understanding Core Web Vitals and Google search results.
- 7.Are Core Web Vitals A Ranking Factor?.
- 8.30 AI SEO Statistics.
- 9.Automated Marketing Reports: 11 Best Tools for 2026.
- 10.The Criteria to Evaluate Enterprise Automation Platforms.
- 11.2024: The State of Generative AI in the Enterprise.
- 12.Enterprise SEO Platform Benefits and When to Invest ....